http://www.zdnet.co.kr/builder/system/server/0,39031667,39133853,00.htm
| [시스템 관리 노하우를 말한다] ② 고가용성·시스템 용량 산정 이진철 (굿어스) 2005/03/18 |
| 연재순서 1회.시스템 유지·보수와 성능 관리 2회. 고가용성과 시스템 용량 산정 3회. 장애 복구와 ITIL 적용 |
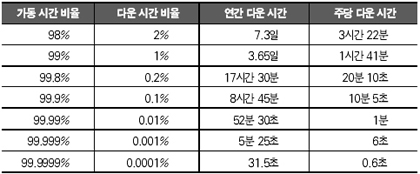
흔히 가용성(Availability)의 척도는 9라는 숫자의 조합으로 평가된다. 가용성을 99%로 유지하는 것과 99.99%로 유지하는 것에는 엄청난 비용과 기술의 차이가 있다. 가용성은 선형적으로 증가하지 않으며, 페일오버(Failover)라 불리는 스위치 오버(Switch Over)에 걸리는 시간과 관련된 문제이기 때문이다. “우리 회사의 시스템은 매우 중요한 업무를 처리하며, 365일 24시간 쉬지 않고 서비스가 진행되어야 하므로 100%의 가용성을 유지해야 합니다”라는 고객의 요구를 어떻게 받아들여야 할까? 이번 글에서는 고가용성(두 시스템간의 Monitoring & Protection)에 대한 논의와 시스템 용량 산정에 대하여 일반적인 원칙과 사례를 들어 설명하고자 한다. 3개월에 걸쳐 다룰 내용은 다음과 같으며, [1]과 [2]는 지난 글에서 다뤘고, 이번에는 [3]과 [4]에 대해 알아볼 차례다. [1] 시스템 유지보수(System Maintenance) 일반론 [2] 성능 관리(Performance Management) 분야 [3] 가용성 관리(Availability Management) 분야 [4] 용량 관리(Capacity planning & Sizing) 분야 [5] 장애 복구(Crash Recovery) 분야. [6] 서비스 엔지니어의 관점에서 바라보는 ITIL의 적용 가용성과 용량 관리 가용성과 용량 관리(용량 산정)라는 분야에서 시스템 관리자가 관심을 가져야 하는 지식의 범위는 의외로 넓다. 흔히 ‘Availability’라는 단어로 포장되어 있는 가용성의 분야에는 SPOF(Single Point of Failure)를 제거하기 위한 어마어마한 노력들이 포함되어 있으며, 용량 산정을 정확히 예측하기 위한 분야에서도 많은 엔지니어의 경험과 숙련도가 요구되어 왔다. 가용성 관리를 위한 주제로 가용성의 측정, 고가용성 시스템의 구축 원칙(일반적인 법칙), 각 시스템 및 구성 요소별(데이터베이스 서버, 웹 서버, 애플리케이션 서버, 네트워크 등) 구축방법(사례) 등을 논의해 보고자 한다. 용량 관리(Capacity planning & Sizing)에 대한 이론적인 접근을 통하여 지난 번에 언급한 성능 관리가 어떻게 연계되어 있으며, 전세계적인 표준 벤치마킹 사이트(www.tpc.org,www.specbench.org,www.spec.org) 등에서 제공되는 정보들이 시스템 사이징에 어떻게 이용되는지 사례별로 살펴보고자 한다. 가용성 관리 분야 가용성 구축 일반론 가용성에 대한 일반적인 공식은 다음과 같다.
여기서 A는 가용성(Availability, %)을 나타내며, MTBF는 Mean Time Between Failures, MTTR은 Mean Time To Recover(복구하는 데 걸리는 시간)를 의미한다. 실제로 MTTR이 최소화될수록 가용성은 100%에 가깝게 된다. 예를 들어, 어떤 시스템의 MTBF가 5만 시간이고, MTTR이 30분이라면 앞의 공식에 따라 이 시스템의 가용성은 99.999%가 된다. 결국 5년 8개월 동안 단 30분의 다운타임이 발생해야만 99.999%의 가용성이 보장된다는 것이다(우리나라 관공서의 장비 의무보존 기간을 평균 5년으로 보았을 때, 이 가용성 수치는 달성하기 불가능해 보인다). 게다가 이 가용성 수치를 99.9999%로 끌어올리기 위해서는 5년 8개월 동안 단 3분의 다운타임이 보장되어야 한다. MTBF의 핵심은 시스템에 고장이 생길 때까지 걸리는 평균시간을 의미한다. M은 평균적인 추세를 의미하기도 하는데, 예를 들어 평균적인 HDD의 수명이 제조사들이 발표하는 것처럼 11.5년이라면 500개의 드라이브가 설치된 디스크 어레이(Disk Array)는 평균 16.5일마다 디스크를 교체해 주어야 한다는 확률이 나온다.
<표 1>은 가장 간단한 의미에서 가용성을 계산하는 방식이다. 최근의 추세는 SLA에 가용성에 대한 질적/양적인 규정을 명시하기 때문에 이 계산 공식은 좀 더 세분화되어야 하며, 더 자세한 상황들이 고려되어야 한다. 실제로 고객이 요구하는 MTBF는 일요일 새벽 1시부터 6시가 아니라, 목요일 오전 9시 30분부터 11시 30분 사이에 더 가치가 있을 것이다. 따라서 “어느 시간대에 100%의 시스템 가용성을 달성할 수 있는가?” 하는 것이 SLA에서 가용성 협상의 관건이 될 수 있을 것이다. 서버 다운의 정의와 원인 분석 서버 다운은 상황의 긴박함 정도를 고려하거나, 다운으로 인한 임팩트가 단순한지 복잡한지에 따라 다양하게 사용된다. 가장 흔한 다운의 정의는 서버 자체나 디스크, 네트워크, 운영체제, 주요 응용 프로그램 등의 서버를 이루고 있는 구성요소에 문제가 생겼을 때를 말한다. 보다 엄밀히 따져보며 서버 및 네트워크의 속도 저하, 백업 시스템의 고장, 일부 데이터를 읽을 수 없는 상황도 다운에 해당된다. 궁극적으로 SLM에서 바라보는 서버 다운은 “사용자(User, Customer)가 계획된 시간 안에 작업을 마칠 수 없을 때”, 이를 시스템 다운으로 정의할 수 있다. 일반적으로 서버 다운의 원인을 분석해 보면 다음과 같은 결과를 얻을 수 있다. ◆ 예정된 다운타임 : 30% ◆ 소프트웨어 다운 : 40% - 서버 소프트웨어 : 30% - 클라이언트 소프트웨어 : 5% - 네트워크 소프트웨어 : 5% ◆ 사람 : 15% ◆ 하드웨어 : 10% ◆ 환경 : 5% 예정된 다운(Planed Downtime)이 많은 비중을 차지하고 있는 것은 정상적으로 볼 수 있다. 소프트웨어로 인한 다운타임이 많은 퍼센트를 차지하는 것은 서버 소프트웨어(운영체제 포함), 클라이언트 소프트웨어, 네트워크 소프트웨어 등의 버그는 시스템 안정성을 위하여 가장 통제하기 힘든 분야이기 때문이다. 하드웨어가 안정화되어 갈수록 소프트웨어로 인한 다운타임의 비중은 높아질 것이며, 또한 소프트웨어가 점점 더 복잡해지면서 소프트웨어 자체 문제로 인한 장애가 더 많이 발생할 것이다. 시스템 다운의 특이할 만한 점은 사람에 의한 비중이 15%나 된다는 것이다. 여기에는 사람들의 직무태만이나 부주의로 인한 실수와 시스템 운영방법을 완벽하게 숙지하지 않아서 발생하는 문제로 크게 나눌 수 있다. 이렇게 사람으로 인한 시스템 다운의 해결책으로는 지속적인 교육과 시스템 구성을 기능에 맞게 단순화시켜 구성하는 방법을 제시할 수 있다. 가용성의 단계 크게 가용성의 단계는 시스템의 severity level에 따라 다음과 같이 크게 4단계로 구분한다(하지만 이 구분이 명확하게 구분해낼 수 있는 기준을 제시하는 것은 아니다. 실제로 가용성을 증가시키기 위한 수많은 단계와 함께 결집된 기술은 그처럼 단순하지 않기 때문이다). 1단계, 일반적인 가용성 : Normal 시스템 시스템이나 디스크를 보호하기 위한 장치는 전혀 없으며, 1단계 백업 이외에는 별 다른 것이 없다. 시스템이 다운되면 백업한 시점 이후의 데이터를 잃을 수도 있고, 특별한 회복능력(resilence)이 보장되지 않는다. 2단계, 가용성 증가 : 데이터 보호 1단계에 비하여 온라인 데이터 보호를 제외하고는 별로 다를 것이 없다. 데이터 보호을 위하여 Raid 5(Parity bit을 이용한 Raid)나 미러링(Mirroring) 같은 수준의 낮은 데이터 보호가 진행될 뿐이다. 디스크가 모두 훼손되었을 경우 치명적인 시스템 다운은 피할 수 없다. 3단계, 고가용성 : 시스템 보호 이 단계는 흔히 HA(High Availability)라고 하는데, 두 대의 같은 기능을 수행할 수 있는 시스템을 클러스터로 구성한 후 한 쪽 시스템이 제 기능을 수행할 수 없을 경우 다른 시스템이 대체 작동하게 함으로써, 시스템이 가지고 있는 대부분의 SPOF(Single Point of Failure)를 제거할 수 있는 매우 큰 장점이 있다. 이 단계에서 일반적인 가용성은 99.98%까지 끌어올릴 수 있으나, 중복 투자되는 비용의 천문학적인 증가를 고려하여야 하며 End-to-End HA 시스템을 구성할 때는 반드시 네트워크까지도 고려하여야만 한다. 4단계, 재난 복구 시스템 재해에 대한 자동 복구 시스템을 구축하는 것은 시스템 보호 단계 중 가장 비용이 많이 소요되며, 최상의 IT 기술력이 결집되어야만 가능하다. 천재지변에 대비하여 시스템은 원격지에 서로 이중화되어야 하며, 백업 시스템은 언제든지 자동으로 메인 시스템을 대체할 준비가 되어 있어야 한다. 이 단계에서는 무정지 시스템(Fault Tolerant System)의 구성을 포함하는 경우도 있는데, 한 시스템 안에 두세 개의 대체 부품을 장착하여 특정 부품에 문제가 생기더라도 각 부품이 대체 동작하거나 병렬로 동작해 시스템의 다운타임을 극소화시킬 수 있는 시스템을 말한다. 그럼 가용성을 증가시켜 나가는 각 단계별 구성요소의 구축방법과 사례를 통해서 고가용성 시스템의 활용 측면을 살펴 보도록 하자. 가용성을 위한 데이터 보호 실제로 고가용성 시스템에서 디스크는 고장날 확률이 가장 높은 구성 요소이다. MTBF를 떨어뜨리는 가장 대표적인 디스크 장치는 그러면서도 데이터 보호와 성능를 위하여 가장 신경을 많이 써야 하는 부분이기도 하다. 일반적으로 디스크 어레이를 구성하는 방식은 Raid Level에 따라 그 가용성의 정도가 달라진다(아래 박스 참조).
물리적인 디스크 레이아웃(Layout)을 재배열할 때는 다음의 고려사항에 유념해야 한다. [1]핫 플러깅 디스크(Hot Plugging Disk) : 시스템이 서비스를 계속 진행 중인 상태에서 디스크의 물리적인 교체 작업이 가능해야 한다. [2]물리적 용량 : 하나의 디스크 사이즈는? 하나의 컨트롤러에 배열될 수 있는 디스크의 갯수는? Raid 레벨에 따른 오버헤드에 의하여 줄어드는 디스크 공간의 크기는? [3]성능 : 하나의 컨트롤러에 전체(Full) 디스크를 배열하고 다른 하나의 컨트롤러에는 두세 개의 디스크만을 나열한다면 어레이 컨트롤러의 커넥션에 의한 성능 저하를 야기시킬 가능성이 있다. [4]캐비넷 스페이스(Cabinet Space) : 슬롯 부족으로 인한 캐비넷의 추가 구매가 발생할 수 있다. 최초 구성시 철저한 계획의 부족이라고밖에 볼 수 없다. [5]케이블 관리 : SAN이나 NAS의 경우 광케이블의 길이 및 관리 또한 충분한 고려대상이다. [6]파워 서플라이 : 데이터센터나 다른 건물들에서 추가될 하드웨어 전체가 사용할 충분한 전력량 확보도 확인해야 한다. Raid 구성에 대한 원론적인 논의보다는 현재 스토리지 시장의 변화와 이슈들을 들여다보는 것이 더 유익할 것이다. 지난 수년간 스토리지를 도입해온 기업들은 SAN(DAS)이나 NAS의 형태로 스토리지 시스템을 구성하면서 서버 접속 및 스토리지 확장의 편리성을 비롯하여 다수의 서버와 다수의 스토리지 접속을 통한 정보 공유거리 제약의 한계 및 성능 한계 극복, 통합 관리에 따른 관리 비용 및 관리노력 감소 등 많은 이점을 제공받았다. 하지만 업무목적과 지역적인 위치에 따라 스토리지가 다르게 도입되었고, 결국 스토리지와 그 주변 자원을 관리하는 업무가 또 하나의 업무가 된 부작용을 초래하였다. 관리 데이터와 네트워크, 시스템, 애플리케이션, 사용자, 장비 및 지원 등의 관리 부분들 내의 데이터 관계를 나타내는 공통 정보모델로써, CIM은 MOF(Managed Object Format)로 UML(Universal Modeling Language)을 이용해 정의되는데, 비용 절감과 가용성을 극대화하기 위해 On-Site나 지리적으로 분산된 스토리지 자원들의 중앙 집중화된 관리를 가능하게 하는 것이다.
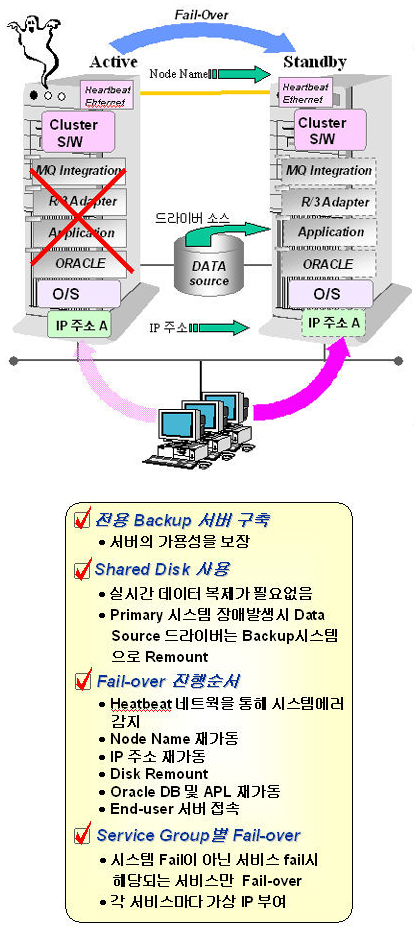
시스템 보호를 통한 고가용성 구현 컴퓨터 시스템의 대부분은 보통 12개 이상의 구성요소(프로세서, 디스크, 메모리, 파워서플라이, 팬, 메인보드, 확장 슬롯, 백본 등)들로 이루어지며, 이 구성요소들 각각의 하부 요소들이 편재돼 있다. 결국 하나의 시스템에는 SPOF를 구성하는 매우 다양한 형태의 부품들이 MTBF의 길목을 노리고 있는 것이다. 만약 대체 서버가 구성되어 있다면 각각의 SPOF에 대한 확실한 Resillience를 확보하여 이론적으로는 최소한 98% 이상의 가용성을 확보할 수 있게 되는 것이다 이러한 페일오버 시스템(Failover System)에 대한 전반적인 구성과 이슈들을 살펴보자. 페일오버의 요구사항 클러스터는 두 서버들이 서로 가까운 곳에 위치해 있어야 하는데, 그 중에서도 두 서버들이 클러스터로 바뀌도록 요구하는 다양한 구성 요소들에 대해서 살펴보아야 한다. 필요한 구성요소들은 다음과 같다. ◆ 서버 : 주(Primary) 서버와 대기(Take) 서버(또는 스탠바이 서버), 이렇게 두 대의 서버가 필요하다. 어떤 경우에는 대기 서버를 대체 서버라고 부르기도 하지만 이는 같은 의미로 볼 수 있다. 주 서버가 제 기능을 수행할 수 없는 상황이 닥치면 주 서버에서 멈춘 응용 프로그램을 대체 서버로 마이그레이션(migration)하는 과정을 페일오버라고 한다. ◆ 네트워크 커넥션 : 페일오버를 구성하는 데에는 세 가지의 다른 네트워크 연결이 요구된다. 첫 째는 쌍으로 엮여진 HeartBeat 네트워크로, 한 서버에서 다른 서버로 바로 통신하지만 이것은 전적으로 상호간에 독립적이며 매우 기본적인 것이라 할 수 있다. 이 네트워크는 서버들이 다른 서버와 연결하게 하고 모니터하도록 하여 쌍을 이루는 상대에게 조치가 필요한 일이 발생하는 것을 즉시 알아차리게 된다. 두 번째 네트워크 연결은 일반 서비스 네트워크를 의미한다. 세 번째는 관리를 위한 네트워크로 페일오버가 발생한 후에라도 시스템 관리자들에게 각각의 서버 간의 네트워크 경로를 보장한다. ◆ 디스크 : 페일오버에는 두 종류의 디스크 유형이 있는데, 첫 번째인 내부 비공유 디스크들을 현재 동작하고 있는 서버가 아닐 경우 각각의 시스템이 시스템 작동을 위해서 페일오버 과정을 초기화하여 유지하게 하는 소프트웨어를 포함하여 운영체제와 필요한 다른 파일들을 가지고 있다. 다른 종류의 디스크는 공유된 디스크들(Shared Disk)이고, 여기에는 중요한 응용 프로그램의 데이터가 자리를 잡고 있다. 페일오버가 발생했을 때 디스크들을 서버들 사이에서 이동(migration)하여 클러스터된 양 서버에 의해 접속이 가능하게 된다. 비록 일반적인 환경에 놓여 있다 하더라도 한 번에 하나의 서버에 접속할 수 있으므로 페일오버 상의 모든 디스크들은 일반적으로 여유분을 가지고 있어야 한다. ◆ 애플리케이션 : 페일오버에서 응용 프로그램은 클러스터 디자인의 중요한 요소로 취급되어야 한다. 그럼에도 불구하고 응용 프로그램에 대한 중요성은 일반적인 페일오버 디자인에서 추가적인 비용문제를 야기시킨다. 대부분의 경우 양쪽 서버에서 동시에 실행될 경우의 애플리케이션 비용과 한 쪽씩 교대로 실행되는 경우의 애플리케이션 비용은 차이가 있다. 양쪽 서버에서 완벽하게 작동되는 제 가격의 라이선스를 구매함으로써 HA를 구성하는 비용은 최초의 예상보다 높아질 것이 분명하다. ◆ SPOF : 페일오버 시스템에서 SPOF는 거의 모든 부분에서 제거되었다고 볼 수 있다. 싱글 노드 서버에서 일반적으로 잘 알려진 SPOF(PROM, CPU, 메모리, SCSI 컨트롤러, 애플리케이션 등)들은 거의 대부분 페일오버 시스템상에서 제거된 것처럼 보인다. 그러나 페일오버 시스템상에서도 여전히 SPOF의 문제점은 남아 있다. 이것은 매우 일반적인 구성 요소로 쌍으로 된 모든 요소와 관련이 있다. 클러스터의 구성 요소가 있다면 두 서버가 사용할 수 없는 경우 고가용성을 가졌다고 볼 수 없기 때문이다. 페일오버 구성 방법 페일오버 환경설정에 사용되는 다양한 방법들 중 몇 가지를 살펴보고, 이를 적용하는 경우의 이슈들을 살펴보자. 한정된 지면상 2 노드(Two-Node) 페일오버를 중심으로 그 구현방식들을 살펴보고자 한다. 2 노드로 운용되는 페일오버 환경 설정은 가장 간단하면서 널리 이용되는 경우이다. 투 노드 환경 설정은 크게 비대칭형(Asymmetric)과 대칭형(Symmetric)의 두 가지로 나뉜다. 비대칭형 2 노드 환경 설정에서는 한 개의 노드가 활성화되어 대부분의 일을 수행하게 되고, 그 동안 다른 하나의 노드는 스탠바이 전용으로, 즉 활성화되어 있던 노드가 고장을 일으키게 되면 바로 이를 대체할 수 있는 대기 상태가 된다. 대칭형 2 노드의 경우에는 양 노드가 완전히 개별적으로 돌아가고 있다가 어느 한 쪽이 고장을 일으키게 되면 살아남은 다른 노드에 이를 고스란히 떠넘겨 두 배의 작업을 처리할 수 있게 함으로써, 고장난 노드가 고쳐질 때까지 버틸 수 있도록 되어 있다. Asymmetric 1-to-1 페일오버
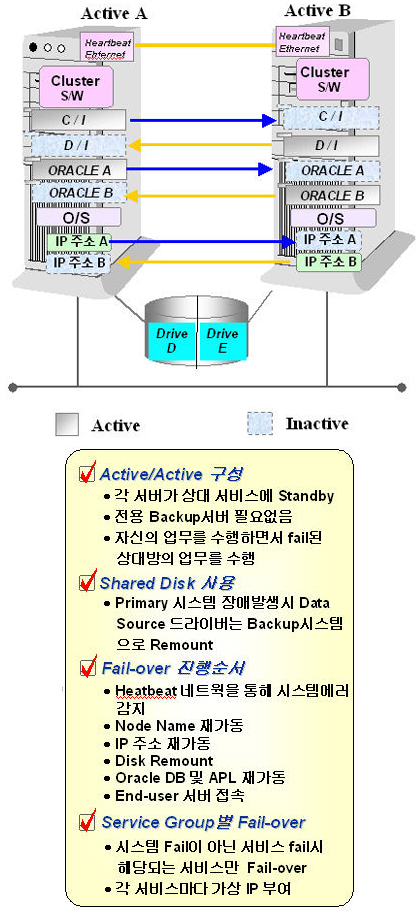
<그림 2>에서 나타나는 페일오버의 예는 가장 단순한 형태이면서 전형적인 액티브-스탠바이(Active-Standby)의 모델을 보이고 있다. 최초 액티브 노드에서는 공유 디스크를 마운트한 상태이며, 서비스 네트워크 IP를 가지고 있다. 물론 응용 프로그램의 실행과 서비스를 진행하고 있으며, 클러스터 소프트웨어는 시스템의 모든 서비스가 정상적으로 진행되는지의 여부를 모니터링하고 있다. 만일 액티브 노드의 모든 SOOF 중 서비스를 정상적으로 제공할 수 없는 장애 상황에 봉착하게 되면 클러스터 소프트웨어는 응용 프로그램의 서비스를 내리고, 공유 디스크(Shared Disk)를 Unmount하며, 서비스 네트워크 IP를 놓는다. 반대로 스탠바이 서버는 서비스 네트워크 IP를 가지고 와서 네트워크 카드에 설정하고, 공유 디스크를 마운트시키며, 응용 프로그램이 서비스를 시작할 수 있도록 준비한다. 각 클라이언트들은 동일한 IP로부터 서비스를 공급받게 된다. 이러한 비대칭 페일오버 시스템에서 가장 큰 고민거리는 같은 비용을 주고 도입한 스탠바이 서버가 놀고 있다는 상황이다. 물론 가용성을 끌어올리기 위하여 지대한 역할을 했다는 것을 엔지니어의 입장에서는 이해할 수 있겠지만, 비용을 지출한 고객의 입장을 정당화하기는 힘든 문제이다. Symmetric 1-to-1 페일오버
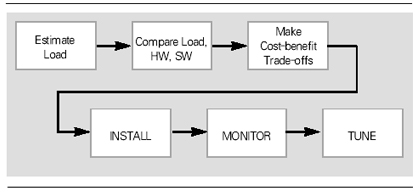
Symmetric 페일오버 시스템은 액티브-액티브 페일오버로서 비용적인 측면보다 효율적인 비용 대 효용을 달성할 수 있으므로 대칭형 페일오버가 바람직하다고 볼 수 있다. 100% 이상의 중복 투자를 하는 대신 이중 연결(Dual-Connect) 디스크와 HeartBeat 네트워크에 들어가는 비용만 추가될 뿐이다. 실제로 대칭형 페일오버 시스템에서 남아 있는 가장 큰 문제점은 Take Over가 발생한 시점 이후로 한 서버가 두 대의 서버가 하던 일을 하게 됨으로써 과부하(Over Load)가 걸릴 수 있다는 것이다. 필자는 이러한 대칭형 시스템이 페일오버된 후 한 노드에서 과부하를 견디지 못하고 두 대의 노드가 순차적으로 다운되는 현상을 목격한 적이 있는데, 이것은 정밀한 용량 산정(Capacity planning & Sizing)이 뒷받침되지 않은 상태에서 페일오버 디자인이 되었기 때문이다. 또 한 가지 남아 있는 문제점은 페일오버가 발생할 경우 첫 번째 노드에서 진행되던 트랜잭션이 취소(rollback)되지 않고, 두 번째 노드로까지 완벽하게 Take over가 될 수 있는지의 문제이다. 이 문제를 해결하는 대표적인 사례가 오라클 9i RAC(Real Application Cluster)인데, 한 노드에서 진행되던 트랜잭션이 롤백되지 않고 다른 노드의 인스턴스에서 이어서 처리되도록 하기 위하여 캐시 퓨전이라는 기능을 사용하고 있다. 결과적으로 응용 프로그램의 트랜잭션 Take Over 문제에 대해서는 애플리케이션의 완벽한 테스트와 적용이 요구된다. 데이터 보호와 시스템 보호를 통해서 고가용성을 구성하는 몇 가지 방법과 사례만을 위주로 살펴보았다(시스템 복구의 구현에 대해서는 다음 글에 언급하고자 한다). 이 안에는 네트워크의 이중화 구성 방법에 대해서는 전혀 언급하지 못한 것이 아쉽다(실제로 필자가 재직하고 있는 회사는 150여명의 뛰어난 네트워크 엔지니어들이 포진하고 있다). 가용성의 다양한 측면을 이해하고, 가용성의 목적인 Business Availability로 그 기능과 역할이 전달될 때, 진정한 엔지니어링의 힘과 효용이 두드러질 것이다. 좁은 의미에서의 가용성을 다루어 보았지만, 관리자로서 반드시 관심을 가지고 그 기술적 추이를 지켜봐야 할 분야이다. 용량 산정 분야 몇 년 전, 한 업체가 신규 데이터베이스 시스템을 도입할 때 직접 설치 지원을 나간 적이 있었다. 그 고객에게 이 시스템의 용량 산정을 어떻게 하였느냐고 물었더니 영업사원이 제안서에 제시한 대로 구입한 것이라는 답변을 했다. 그 영업사원에게 어떤 방식으로 용량 산정을 했냐고 또 물었더니 고객이 제시한 가격에 맞추어서 부품들을 끼워넣었다고 했다. 이것이 우리의 현실이다. 기업의 규모가 크고 재정적인 뒷받침이 확고한 전산실에서는 정확한 컨설팅을 의뢰하여 시스템 도입을 진행하지만 대다수의 기업에서 시스템을 도입할 때는 ‘주먹구구’가 현실인 것이다. 결국 필자가 설치 지원을 나갔던 그 업체는 2년이 채 지나지 않아서 CPU와 메모리 그리고 신규 디스크 어레이의 도입을 검토하게 되었고, 최근에는 다시 새로운 시스템의 도입을 고려하고 있다고 한다. 시스템의 용량 산정에 대한 기술은 매우 전략적인 접근이 필요하다. Capacity Planning & Sizing에 대한 이론적, 기술적인 정보들은 IT 기업의 핵심 기술력에 포함되며, 실제로 잘 공유되지 않는(오픈되지 않는) 기술군 중 하나이다. 하나의 시스템을 계획할 때, 그 구성요소 각각에 대한 정밀한 용량 산정 없이 장비 도입이 이루어진다면 이러한 사례는 불을 보듯 뻔한 현상으로 다가올 것이다. 정확한 용량 산정을 위해서는 매우 다양한 시스템 구성요소들을 살펴보아야 하지만, 여기에서는 CPU, 메모리, 디스크 용량에 대한 사이징 방법과 국제적인 벤치마크 테스트가 어떻게 사용되는지 살펴보도록 하겠다. 용량 계획 프로세스와 고려사항 용량 산정을 위해서 일반적으로 <그림 4>와 같은 프로세스를 적용시키는 것이 보편적이다.
[1] Estimate Load : 작업(업무) 로드량을 측정한다. 여기에는 실제로 시스템에 적용될 응용 프로그램과 그 환경(투-티어, 쓰리-티어인지, 미들웨어나 WAS 제품의 특성, 로드량의 증가분과 변수)들도 고려되어야 한다. [2] Compare Load HW, SW : 분석된 작업(업무) 로드량을 바탕으로 하드웨어와 소프트웨어의 용량을 분석한다. 측정된 성능 측정표를 기반으로 시스템의 물리적, 논리적 용량 산정이 분석된다. [3] Make Cost/Benefit Trade-off : 최상의 효율을 고려한 하드웨어/소프트웨어의 용량과 최적의 투자비용에 대한 Trade-off를 준비한다. 이후 설치, 모니터, 튜닝 과정을 통해 시스템의 안정화를 유도한다. 또한 안전한 시스템의 예측(Prediction)을 위해서는 다음의 4가지 요소들이 주의 깊게 다루어져야 한다. [1] Consider All Resources : 현재 병목현상을 발생시키는 요소가 아니더라도 모든 자원을 대상으로 용량 산정 계획을 진행하여야 한다. 현재 디스크 I/O 자원의 Utilization이 100%에 도달했다고 해서 디스크 자원만 증설하는 것보다 앞으로 사용량이 늘어날 가능성이 있는 CPU나 메모리 자원에 대해서도 동시에 고려하는 것이 바람직하다. [2] Application Environments : 얼마나 많은 사용자가 사용하는가? 이 애플리케이션은 OLTP 목적인가? DSS 목적인가? 시스템을 이용하는 애플리케이션은 CPU intensive한가? I/O intensive한가? 이 애플리케이션은 Short Job인가? Long Job인가? 등 애플리케이션의 특성은 시스템의 성능과 용량 사전 계획에 궁극적인 결정 포인트로서 작용한다. [3] Annual Inflation : “WorkLoad가 어떤 형태로 늘어나는가?” 하는 것은 매우 중요한 요소 중 하나이다. 예를 들어 매년 15%씩 업무 증가량이 발생한다고 했을 때, 사용자가 15% 늘어날 수도 있고, 프로그램의 트랜잭션량이 늘어난 것일 수도 있으며, 처리해야 할 데이터량이 늘어난 것일 수도 있다. 결국 늘어난 Job Load의 특성에 따라 CPU, 메모리, 디스크 I/O, 네트워크 등의 용량 산정 요소가 바뀔 수 있다. [4] Performance of complex system : 성능분석 포인트는 용량 산정과 가장 깊은 관계를 맺고 있는 분야이다. 부정확한 성능 분석 데이터로부터 정확한 시스템 용량 산정 계획이 이루어질 수 없다. 복잡한 시스템에서 한 요소에 대한 성능 분석은 서브 시스템 부분에 대한 구체적인 성능 통계 데이터들의 취합으로부터 이루어져야 하므로 보다 더 정밀한 분석을 요한다. 예를 들어 I/O 성능에 대한 분석이 I/O 용량 산정으로 이어지기 위해서는 I/O 보드, SCSI 컨트롤러, I/O 버스, 디스크 어레이, 디스크 자체 등 I/O 활동을 구성하고 있는 모든 서브 시스템에 대한 구체적인 성능 분석들이 정확하게 이루어져야 한다. 각 요소별 용량 산정 사례 정밀한 시스템의 용량 산정을 하기 위해서는 앞에서 설명한 용량 산정시 고려사항 항목들을 모두 검증해야만 한다. 서브 시스템의 세부 용량이라든가, 애플리케이션의 특성 분석 및 반영 등이 빠져서는 결정적으로 완벽한 시스템 용량 산정이 이루어졌다고 볼 수는 없다. 그러나 일반적으로 시스템의 용량 산정을 진행할 때 서브 시스템의 구체적인 성능 및 용량은 제조사의 테스트 결과를 신뢰하거나 국제적인 벤치마크 결과를 반영하므로, 시스템의 CPU, 메모리, 디스크 공간에 대한 사이징만을 진행한다. 그리고 애플리케이션에 대한 벤치마크 결과는 소프트웨어 생산 업체의 자체적인 테스트를 통하여 보정률을 적용한다. 이에 근거하여 보편적으로 시스템 구축시 CPU, 메모리, 디스크 공간의 용량 산정 방법을 알아보자.
※ tpmC = 동시사용자수×분당 트랜잭션(사용자수×트랜잭션 복잡도(50%))+인터페이스(가중치%)×네트워크 보정(30%)×피크 타임 보정(50%)×I/O 부하(20%)×년간 업무증가 및 여유율(연 20%) ※ 메모리 용량 = {(OS 커널(100M)+[ SGA() ]+사용자수×5MB)+[Webserver()]+인터페이스(가중치%) }+여유율(30%) ※ AP 서버 디스크 용량 = {OS 커널(제조사 표준 값)+[Pkg(제조사 표준 값)]+[웹 서버(제조사 표준값)]+메모리 Swap(실제 메모리의 두 배) }×여유율(30%) ※ DB 서버 디스크 용량 = {(Data file() + archive file() + RAID 보정}×여유율(30%)
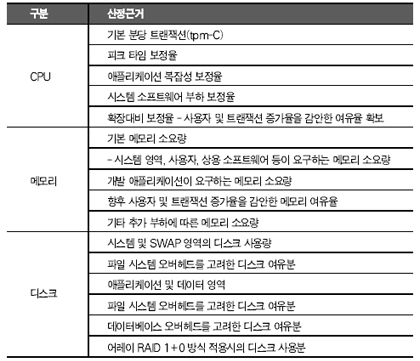
<표 2>의 기준들은 다시 강조해서 말하지만, 보편적인 형태의 용량 산정시 기준들이다.www.tpc.org에 제공되는 벤치마크 기준은 TPC-C(OLTP 기반), TPC-W(웹 기반), TPC-H(대량의 데이터 처리 기반) 등의 다양한 표준을 제시한다. 그리고 피크 타임 보정율, 애플리케이션 복잡성에 따른 보정율, 시스템 소프트웨어 보정율 등은 해당 제조사와 소프트웨어 개발 업체의 테스트된 신뢰성 있는 정보를 기반으로 설정되어야 한다. 그럼 각각에 대한 구체적인 적용사례들을 살펴보자. CPU 용량 산정 사례 이 CPU 용량 산정 사례는 2001년 1월에 발표된 S사의 엔터프라이즈 모델의 tpmC 값 21871.90을 기준으로 한 기업의 데이터베이스 서버의 트랜잭션량을 분석한 결과이다. 용량 산정시 고려되었던 핵심 기준은 1000만명의 고객이 동시에 액세스할 때의 Job Load량의 Inflation이었다. 기준이 되는 일 발생 트랜잭션 처리 수(629,760)는 DB 엔진을 대상으로 분석한 결과 값이며, DB 크기와 트랜잭션 분석(조회 15 : 저장 1건)의 비율이 적용되었다. CPU당 처리될 수 있는 분당 트랜잭션량을 비교한 결과 1000만 고객을 대상으로 할 경우 현재 트랜잭션의 3배를 가중시킨 결과 현재 CPU 사용률(Idle Time 90% 이상)을 고려해 8개의 CPU 구성을 결정하였다. 물론 이러한 구성이 완벽한 CPU 용량 산정이라고 볼 수는 없으나, 애플리케이션 개발 업체의 검증된 보정율과 하드웨어 제조사의 스펙을 기준으로 최대한 객관적인 수준의 사이징을 유도하였다고 판단된다. 메모리 용량 산정의 사례
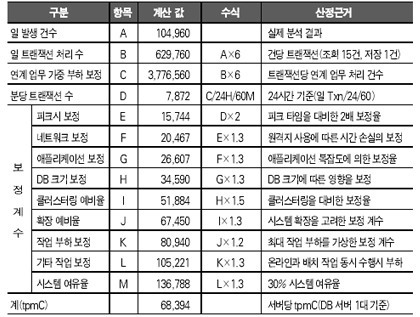
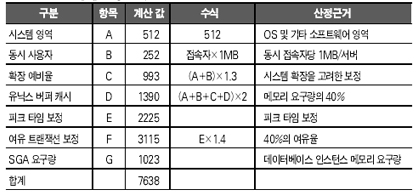
용량 산정 당시 시스템에서는 6GB 메모리 중에 실제 DB 시스템에서 사용되는 메모리량은 1/3을 약간 웃도는 상태였는데, 현재 상태의 메모리 크기로도 800만명의 고객을 대상으로 충분한 서비스가 가능하지만 1000만명을 대상으로 하는 tpmC 값을 고려할 때 7638MB의 메모리를 산정하여야 했다(이 값에는 여유율 40%가 포함된다. 이 값은 과도하게 산정된 감이 없지 않다). 데이터베이스 서버의 메모리 산정에서 가장 중요한 것은 데이터베이스 인스턴스 메모리와 그 여유율, 그리고 동시 접속자들의 세션 수에 비례하는 Private Memory의 총합이라고 볼 수 있다. 따라서 앞 사례의 경우 데이터베이스 엔진의 특성이 메모리 용량 산정의 관건이라고 볼 수 있다. 디스크 용량 산정의 사례
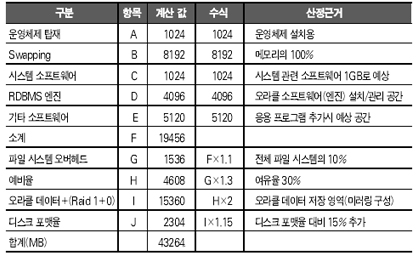
이 시스템의 Internal Disk로 구성되어 있는 데이터베이스 서버의 저장 공간은 총 64GB이며, 이 중 오라클 데이터를 저장하기 위한 할당된 공간은 24GB(24GB 중 13GB 사용, 사용률 55%)로 분석되었다. 이 때 사용 공간에 대한 용량 산정은 Raid 1+0로 구성할 것인지, Raid-5로 구성할 것인지에 따라 많은 편차를 보이게 될 것이며, 레이드 구성 방식이 성능에 미치는 영향력 또한 간과할 수 없을 것이다. 또한 데이터 및 트랜잭션이 3배 이상 증가하는 1000만 고객 시점에 디스크 I/O 병목현상을 예상하여야 하며, 따라서 현재의 I/O Throuput 및 Utilization을 고려하여 속도가 빠른 외장형 디스크 어레이를 적용하여야 한다. 현재 초당 I/O량이 5.46mb/s인 것을 감안하였을 때, 앞으로 3배의 I/O량이 늘어났을 경우 16.38mb/s를 처리할 수 있는 고성능의 외장형 디스크 어레이가 요구된다. 용량 산정의 새로운 이슈, SLM 이상에서 시스템을 구성하는 세 가지 요소(CPU, 메모리, 디스크)에 대한 용량 산정의 일반적인 규칙들과 사례를 통하여 살펴보았는데, 최근 들어 용량 산정에 영향을 미치는 새로운 이슈로 등장한 것이 바로 SLM(Service Level Management)이다. 시스템이 어떤 부품들로 구성되어 있는지, 어떤 데이터베이스가 운용되고 있는지, 네트워크 백본이 어떻게 구성되어 있는지도 중요하다. 그러나 고가용성 시스템을 구성하는 경우에도 SLM이 적용되었듯이, 용량 산정의 보다 근본적인 기준은 비즈니스 목표를 달성하기 위한 서비스 레벨이 맞추어져야 한다는 것이다. IT 인프라스트럭처 전체를 놓고 하나의 서비스가 완벽하게 전달될 때까지 서비스 레벨은 조율되어야 하며, 이에 따라 고가용성 시스템의 용량 산정이 이루어져야 한다. 이 같은 변화의 원인은 이제 우리 IT 서비스 시장이 성숙되어 가고 있는 데서 기인한다고 본다. 주먹구구식 시스템 디자인으로 불과 1~2년 만에 증설이나 시스템 변경이 횡횡하던 시절은 하루 빨리 벗어나야 할 것이다. @ |

'System Admin' 카테고리의 다른 글
| [AIX] Optimizing AIX 5L performance: Monitoring your CPU (0) | 2007.08.03 |
|---|---|
| [시스템 관리 노하우를 말한다] ③ 장애 복구와 ITIL 적용 (0) | 2006.07.07 |
| [시스템 관리 노하우를 말한다] ① 시스템 유지·보수와 성능 관리 (0) | 2006.07.07 |