http://www.zdnet.co.kr/builder/dev/java/0,39031622,39130026,00.htm
| 자바 2 SDK 1.5의「데드락 해결 비법」 윤경구 (티맥스소프트) 2004/09/01 |
다중 쓰레드 환경에서 경쟁 조건과 데드락(deadlock)은 피할 수 없는 관계이다. 여러 개의 쓰레드가 동시에 동일한 변수, 객체 혹은 자원을 차지하려고 하는 경우 경쟁 조건이 발생하며 경쟁 조건에서 한 쓰레드의 배타적 리소스 점유를 보장하는 방법으로 동기화를 사용하게 된다. 동기화를 잘못 처리하는 경우 어느 쓰레드도 진행되지 못하는 교착 상태 즉, 데드락에 빠지게 되는데 조금 복잡한 쓰레드 구조를 다루다 보면 종종 골머리를 앓게 되는 문제일 것이다. 최근 들어 여러 개의 CPU를 장착한 컴퓨팅 환경이 일반화되면서 하나의 CPU에서는 문제없이 실행되던 프로그램들이 데드락과 같은 오류를 보이는 경우도 종종 발견된다. 하나의 CPU에서는 쓰레드간의 진정한 동시성이 없으므로 경쟁 조건이 데드락으로 발전하지 않거나 확률이 아주 낮았지만, 다중 CPU 환경에서는 여러 개의 쓰레드가 그야말로 동시에 자원에 접근하는 경우가 잦으므로 감춰줬던 문제들이 발견되는 것이다. 이번 글에서는 쓰레드의 동시성 문제에 관련된 조금 복잡한 이슈들을 다루고, 동시성 문제를 해결하기 위한 잘 정의된 구조들, 특히 자바 2 SDK 1.5에 새로 포함되는 java.util.concurrent 패키지에 대해 소개한다. 동기화 경쟁 조건 여러 개의 쓰레드가 동시에 실행되는 경우, 운영체제의 스케줄링 정책과 실행 환경에 따라 쓰레드의 실행 순서가 변경되므로 원하지 않는 결과를 낳는 경우가 발생한다. 프로세스 단위에서 관리되는 리소스의 경우 각 쓰레드는 항상 리소스에 대해 경쟁하게 된다. 하나의 파일을 열어 입력 스트림을 만든 다음 두 개의 쓰레드에서 동시에 읽어들인다면 어느 쓰레드가 어느 부분을 읽게 될지 알 수 없다. 리소스가 아니라고 하더라도 프로그램 내에서 두 개의 쓰레드가 공유하는 변수나 객체에 대해서도 경쟁은 언제든지 발생할 수 있다. 다음 상황을 생각해 보자. ◆ 쓰레드 T1과 T2가 동시에 실행되며 둘 다 value라는 정수 값에 대해 참조를 가지고 있다. ◆ T1은 value에 5를 더하는 연산을 수행하며 T2는 value에 5를 곱하는 연산을 수행한다. 초기 value 값이 0이었다면 결과는 어떻게 될까? T1과 T2의 어느 산술 연산이 먼저 스케줄링되느냐에 따라 (0 + 5) × 5 = 25가 될 수도 있고 (0 × 5) + 5 = 5가 될 수도 있다. 이렇게 여러 개의 쓰레드가 스케줄링되는 순서에 따라 결과가 변할 수 있는 상황을 경쟁 조건(race condition)이라고 부른다.
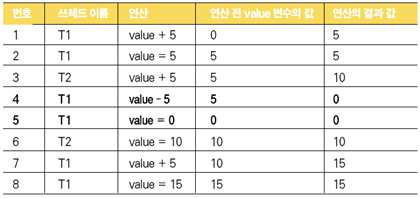
실제의 경쟁 조건 <표 1>과 <표 2>에서 설명한 경쟁 조건은 개념적인 것으로 실제로 발생하는 자바 프로그램의 쓰레드 간 경쟁 조건은 조금 더 복잡하게 표현될 수 있다. 그 이유는 각 쓰레드가 수행하는 value += 5; 혹은 value *= 5; 명령들이 자바 가상머신 수준에서 원자성을 보장할 수 있는 인스트럭션이 아니기 때문이다. 먼저 다음 자바 프로그램을 실행해 보자.
예제에 등장하는 쓰레드는 모두 3개이다. 처음 자바 프로그램이 실행될 때 실행되는 주 쓰레드가 있고 Runnable을 구현한 객체를 인자로 하여 실행하는 두 개의 쓰레드 T1, T2가 있다. 두 개의 쓰레드는 각각 무한 반복문을 돌면서 서로 공유하는 변수인 value에 경쟁적으로 5를 더했다가 다시 빼는 간단한 연산을 한다. 주 쓰레드는 무한 반복문을 돌면서 현재의 value 값을 검사한다. 만약 경쟁이 없다고 생각하면 value 값의 범위는 5를 더하자마자 다시 빼기 때문에 0 혹은 5의 값을 가져야 한다. 하지만 이 경우는 경쟁을 하기 때문에 한 쓰레드가 더하기를 하고 있을 때 다른 쓰레드가 더하기를 실행할 수도 있어 10이 될 수도 있다. 여기까지는 쉽게 추론할 수가 있다. 주 쓰레드는 value의 값이 0에서 10을 벗어날 경우에 표준 출력으로 그 값을 출력하는 일을 한다. value의 범위를 계산하기 전에 값을 다른 변수로 복사한 것은 다른 쓰레드에 의해 그 값이 계속 변하기 때문에 복사를 하지 않으면 두 개의 비교 연산자를 수행하는 동안 value 값이 변할 수 있기 때문이다. 컴파일해서 실행해 보자. 기대한 결과를 보여주는가? > javac NotSynchronizedBlock.java > java -cp . NotSynchronizedBlock 실행 결과는 운영체제마다 차이가 날 수 있지만 대부분의 경우 조금만 기다리면 10보다 크거나 0보다 적은 value 값들을 열심히 출력할 것이다. 그러면 [1] 변수 value의 값을 레지스터로 로드한다. [2] 상수 5를 더하는 연산을 레지스터에 대해 수행한다. [3] 연산의 결과 레지스터 값을 메모리 변수 value에 저장한다. 두 개의 쓰레드 T1, T2가 각각 다음과 같이 스케줄링되는 경우를 생각해 보자. 레지스터의 값은 쓰레드별로 유지되고, value 변수의 값은 공유된다는 점을 기억하자.
<표 3>의 스케줄링 시나리오에 따르면 T2 쓰레드가 연산을 수행한 결과를 값에 대입하는 동안, 즉 3번과 6번 연산 동안에 T1 쓰레드에서 실행된 연산들, 즉 4번과 5번 연산의 결과가 결과적으로 무시가 되었다. 이러한 이유로 value의 값은 10을 훨씬 벗어난 값도 가질 수 있는 것이다. 많은 쓰레드 경쟁 조건과 데드락 문제를 해결하는 방법 중 하나는 이러한 논리적인 연산들의 실행 순서를 <표 3>과 같이 실제 발생 가능한 시나리오를 작성한 후 그 시나리오에 대처하는 방법을 연구하는 것이다. 여기에서 발생하는 문제를 해결하는 방법은 다음과 같다. 각 연산들이 수행되는 동안 다른 쓰레드가 다른 연산을 수행하는 것을 막아서 무시되는 연산을 없애는 것이다. 이때 물론 자바의 쓰레드 동기화에 사용되는 synchronized 블럭을 적용하면 된다. 원인에 대한 분석이 맞았다면 무시되는 결과를 유발하지 않도록 value += 5; 혹은 value -= 5; 연산이 모두 동기화의 단위가 되면 value가 0보다 작거나 10보다 큰 경우가 발생하지 않을 것이다. 동기화 블럭을 적용하는 가장 중요한 원칙은 동기화 블럭의 범위를 가능한 한 짧게 하는 것이다. 앞에서 T1, T2 쓰레드의 run() 메쏘드 안에 있는 value += 5;, value -= 5; 두 명령을 모두 synchronized 블럭 안에 묶어도 문제를 해결할 수 있지만 각 단위별로 묶는 것이 동기화 블럭의 범위를 좁혀서 보다 나은 효율을 기대할 수 있다. 수정한 버전을 컴파일해서 실행해 보면 아무런 메시지도 출력하지 않음을 볼 수 있을 것이다.
데드락 데드락은 둘 이상의 쓰레드가 실행을 멈추고 결코 발생하지 않을 조건을 기다리기 때문에 더 이상 진행할 수 없는 교착 상태에 빠지는 것을 의미한다. 데드락은 다양한 이유로 발생할 수 있다. 예를 들어 T1 쓰레드가 a 모니터의 잠금을 얻은 후 b 모니터의 잠금을 얻으려 하고, T2 쓰레드는 b 모니터의 잠금을 얻은 후 a 모니터의 잠금을 얻으려 하는 상황을 생각해 보자. T1 쓰레드는 T2 쓰레드가 b 모니터의 잠금을 풀기를 기다리고, T2 쓰레드는 T1 쓰레드가 a 모니터의 잠금을 풀기를 기다린다. 두 쓰레드는 무한히 기다릴 수밖에 없다. 이 상태가 바로 데드락이다. 데드락은 동기화 블럭이 잘못 사용되는 경우에 종종 발생한다. 다음 예제는 데드락 상황을 임의로 만든다.
예제에서 T1 쓰레드는 먼저 모니터 객체 a에 대한 잠금을 얻은 다음 1초 정도 쉰 후 모니터 객체 b에 대한 잠금을 얻으려고 시도하고, T2 쓰레드는 모니터 객체 b에 대한 잠금을 얻은 다음 역시 1초 정도 쉰 후 모니터 객체 a에 대한 잠금을 얻으려고 시도한다. 1초 정도 쉬는 이유는 각 쓰레드가 하나의 잠금만을 얻도록 유도하기 위해서이다. 물론 운영체제와 실행 환경에 따라 달라질 수 있기 때문에 1초 쉰다고 반드시 이 데드락 상황을 보장해 주는 것은 아니다. 여기에서는 편의상 데드락의 확률을 높여주기 위해 두 쓰레드가 1초씩 쉬었다. 컴파일해 실행해 보면 대부분의 경우 메시지만 출력되고 그 다음으로 진행이 되지 않을 것이다. T1 acquired a T2 acquired b 자바 가상머신은 현재 진행 중인 쓰레드들의 콜 스택을 덤프해서 보여주는 편리한 기능을 가지고 있는데, 유닉스나 리눅스 환경에서는 QUIT 시그널을 해당 자바 프로세스에 보내면(혹은 자바 프로그램을 실행시킨 콘솔에서 Ctrl+\ 키를 누르면) 해당 콘솔로 콜 스택을 덤프해서 보여준다. 윈도우 환경일 경우 자바를 실행시킨 명령 프롬프트 창에서 Ctrl+BREAK 키를 누르면 해당 명령 프롬프트로 콜 스택을 보여준다. <리스트 4>는 필자의 윈도우 환경에서 이 데드락 상황에 대한 쓰레드 덤프 예이다.
<리스트 4>에서 볼 수 있듯이 자바 2 SDK 1.4.2 HotSpot 가상머신은 친절하게 데드락을 검출하여 별도로 표시까지 해준다. 하지만 가상머신이 다를 경우 항상 기대할 수 있는 것은 아니므로 쓰레드별 정보를 읽어서 데드락 상황을 찾아볼 필요가 있다. 맨 앞부분의 따옴표로 나타난 부분이 쓰레드 이름이다. 쓰레드 이름을 지정해주지 않을 경우, 내부적으로 이름을 할당하게 되는데 여기에서는 쓰레드 객체를 만들 때 T1, T2라는 이름을 명시하였으므로 찾아보기 편하다. 쓰레드 프로그래밍할 때 쓰레드 이름을 어떤 명명 관례에 따라 지정하도록 권장하는 것은 좋은 프로그래밍 습관이다. T2 쓰레드의 콜 스택 정보에서 가장 밑 부분에 0x10030e50이라는 Object의 모니터 객체에 대해 잠금을 얻었고, 그 윗줄에 0x10030e48이라는 Object의 모니터 객체에 대해 잠금을 얻기 위해 기다리고 있다는 정보가 있다. T1 쓰레드의 콜 스택 정보에서는 그 반대의 정보를 얻을 수 있다. 이것을 유추하여 데드락 상황을 판단하고 그 원인을 찾아 해결하는 노력이 쓰레드 문제 해결을 위해 요구된다. 동기화의 비용 동기화를 사용하는 것은 사용하지 않는 것에 비해 상당한 비용이 든다는 것은 모두 알고 있을 것이다. 특별히 별도의 예를 들지 않더라도 java.util 패키지의 여러 컬렉션 클래스들에 대해 동기화를 한 버전과 하지 않은 버전이 상당한 수행 성능 차이가 있음은 익히 들어 알고 있을 것이다. 대부분의 경우 동기화를 최소화하는 것이 가장 좋은 성능을 보여주며 잘못된 동기화 사용은 데드락과 같은 치명적인 결함을 유발하게 된다. 또 앞에서 지적한 대로 synchronized를 사용한 동기화 블럭의 경우 가능하면 그 영역이 좁을수록 또 실제 수행 시간이 짧을수록 좋다. 다음에 나오는 두 메쏘드 doit()과 doit2()는 동기화의 관점에서 볼 때 동일한 일을 한다. 그렇다면 doit()이 좋은 형태일까? 혹은 doit2()가 좋은 형태일까? void doit() { synchronized(this) { doSomething(); } } synchronized void doit2() { doSomething(); } 일반적으로 메쏘드 전체에 대한 동기화를 할 경우에는 doit2()의 경우와 같이 메쏘드에서 직접 synchronized 제한자를 사용하는 것이 보다 나은 성능을 보장한다는 측정 결과가 있다. 이것은 자바 가상머신이 수행하게 될 자바 바이트 코드의 차이에서도 확인할 수 있다. 앞의 두 메쏘드를 자바 2 SDK에 포함된 javap 프로그램을 사용하여 역컴파일해 보면 <리스트 5>와 같이 나타난다. 이 결과에서 볼 수 있듯이 가상머신이 수행해야 될 인스트럭션의 개수가 크게 차이가 나고 가상머신이 최적화를 수행할 여지 또한 줄어든다는 것을 볼 수 있다.
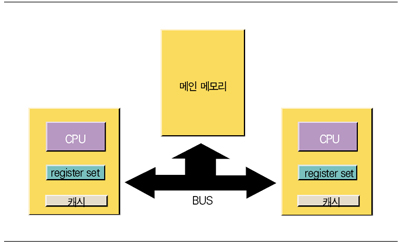
자바 메모리 모델 다중 쓰레드 환경에서 자바는 최적화를 위해 여러 가지 기법을 허용한다. 이러한 최적화 기법은 여러 개의 CPU로 구성된 대칭형 다중 프로세서(SMP) 머신에서 실행될 경우 좀 더 복잡한 문제를 낳을 수 있다. 자바 메모리 모델은 추상화된 개념으로 각 자바 가상머신이 지켜야 하는 최소한의 규칙을 정의한다. 따라서 실제 자바 가상머신은 자바 메모리 모델보다 더 엄격한 규칙으로 구현될 수 있다. <그림 1>은 두 개의 CPU가 있는 SMP 머신을 보여준다.
자바의 각 변수는 메모리에 저장되어 있지만 연산시에는 레지스터에 적재되어 CPU에서 연산을 수행한 후 다시 메모리로 저장되어야 한다. 다중 프로세서 환경에서 고려해야 할 몇 가지 쓰레드 이슈는 다음 세 가지로 분류된다. [1] 원자성 메모리에 있는 필드 변수를 읽거나 쓸 때, 한 쓰레드가 해당 필드 변수에 대해 쓰는 명령을 수행하는 동안 다른 쓰레드가 같은 변수에 대해 읽거나 쓸 경우 그 결과가 어느 한 쓰레드의 동작으로 보장되어야 한다. 즉, 읽거나 쓴 결과가 쓰는 도중의 것이 되어 일부 비트만 변경된 값이 되거나 두 쓰기 명령의 결과가 섞여서 원하지 않는 값이 되지 않는다는 것이 보장되어야 한다. 어떤 명령은 이것이 보장되고 어떤 명령은 일부만 변경되는 값이 나올 가능성이 존재한다. 이것을 원자성(atomicity)이라고 부른다. [2] 가시성 두 개의 쓰레드가 각각 다른 CPU에서 실행되면서 같은 변수에 대해 연산을 수행할 경우 연산 결과를 메모리로 저장하는 시점이 최적화되어 한 쓰레드가 연산을 수행한 결과를 다른 쓰레드가 바로 볼 수 없는 경우가 있다. 이것을 쓰레드의 가시성(visibility)이라고 부른다. [3] 실행 순서 코드 상의 연산 순서가 실제로 CPU에서 수행되는 순서와는 다를 수 있다. 이것은 컴파일러의 최적화에 의해 발생하는 것으로 하나의 쓰레드에서는 관계가 없지만 다른 쓰레드가 같은 변수를 참조할 경우 연산의 실행 순서의 차이가 문제가 될 수 있다. 이것을 쓰레드의 실행 순서(ordering)라고 부른다. 자바로 여러 개의 쓰레드가 관련된 프로그램을 작성할 때 이 세 가지 요소를 모두 고려해야 한다. 먼저 원자성의 경우 자바 메모리 모델은 64비트인 long과 double을 제외한 기본 자료형에 대해 읽기와 쓰기의 원자성을 보장한다. 또 long과 double 필드가 volatile로 선언된 경우에도 이 필드에 대한 읽기와 쓰기의 원자성을 보장한다. 읽기와 쓰기의 원자성이 보장되는 int와 같은 자료형 필드를 한 쓰레드가 값을 변경했을 때 다른 쓰레드가 바로 그 결과를 볼 수 있는 것은 아니다. 이것이 바로 가시성 문제로, 다른 쓰레드가 그 결과를 볼 수 있다고 보장되는 경우는 volatile 필드인 경우와 synchronized 블럭으로 동기화하는 경우이다. 자바 메모리 모델은 volatile 필드의 경우 한 쓰레드에서 쓰기를 한 경우 바로 다른 쓰레드가 볼 수 있음을 보장한다. 또 자바 메모리 모델은 synchronized 블럭 수행 도중 잠금 객체를 풀 때 동기화 구간에서 변경한 결과가 모두 메모리에 반영됨을 보장한다. volatile도 synchronized 블럭도 사용하지 않은 경우에는 자바 메모리 모델은 변화가 메모리에 반영되는 정확한 시점에 대해 아무런 보장을 하지 않는다. 따라서 다음 두 메쏘드는 서로 다르게 동작한다. 원자성의 관점에서 보면 synchronized는 불필요한 오버헤드가 되지만 만약 이 값의 변화를 다른 쓰레드가 바쁘게 기다리고 있다면 그 값이 전달되는 시점이 보장되는 synchronized 버전을 사용해야 할 것이다. synchronized void setValue(int a) { this.a = a; } void setValue(int a) { this.a = a; } 쓰레드의 실행 순서의 경우에도 마찬가지 문제가 발생한다. 자바 메모리 모델은 volatile 필드에 대한 연산의 경우 그 실행 순서를 보장한다. 또, synchronized 블럭에서 잠금을 얻고 풀 때는 동기화를 통해 순서의 문제가 발생하지 않으며, 단일 쓰레드에서 실행될 경우에도 순서의 문제는 발생하지 않는다. 하지만 동기화를 사용하지 않는 다른 쓰레드가 바쁘게 실행 순서에 관련된 필드들을 검사하고 있고 또 변화시키려 한다면 어떤 결과가 나올지 메모리 모델은 보장하지 않는다. 정리하자면 volatile과 동기화 블럭은 여러 쓰레드가 공유하는 변수에 관련된 원자성, 가시성, 그리고 실행 순서에 대해 자바 메모리 모델이 보장한다. 그렇지 않은 경우에는 레지스터의 값이 메모리로 반영되기 전에 다른 쓰레드가 다시 수정하거나 실행 순서가 달라질 수 있다. 각 프로그램의 필요에 따라 동기화의 오버헤드를 고려하여 적절한 방식을 선택해야 한다. 특히 블로킹 연산을 사용하지 않고 어떤 조건을 만족할 때까지 무한 반복문을 돌면서 바쁘게 검사하는 busy wait 방식의 경우에는 volatile 필드의 사용이 필요하다. 주의할 것은 자바 메모리 모델에서 정하고 있는 volatile 필드의 동작 방식을 제대로 구현하고 있는 자바 가상머신이 많지 않다는 점이다. 자바 2 SDK에 포함된 가상머신의 경우 1.4 버전부터 자바 메모리 모델을 제대로 처리하고 있다. 자바 메모리 모델의 내용은 현재 자바 스펙 요청(JSR) 133번에서 계속 논의가 진행되고 있다. 불분명한 자바 언어 명세의 자바 메모리 모델 관련 내용을 더 엄밀하게 정의하기 위한 논의인데, 많은 부분은 자바 2 SDK 1.4 버전에 이미 구현된 것을 좀 더 논리적으로 엄밀하게 하는 내용이 될 것이다. JSR 133번에서 작성 중인 자바 메모리 모델 관련 문서는 참고 자료에 있는 URL을 참고하기 바란다. 선언 : ‘이중 검사 방식의 잠금은 동작하지 않는다’ 선언 자바 메모리 모델에서는 volatile 변수에 접근할 때나 synchronized 블럭에서 잠금 객체를 획득하거나 풀 때를 제외하고는 극단적이라고 할 만큼 관대한 규칙을 적용한다. 이와 관련하여 유명한 논쟁은 이중 검사 방식의 잠금이 자바 메모리 모델 아래에서는 동작하지 않는다는 것이다. 이중 검사 잠금이란 어떤 객체를 필요한 경우에만 생성하는 lazy initialization 방식으로 만들 때, 여러 개의 쓰레드가 접근할 경우를 고려하여 동기화를 최소화하는 경우이다. 예시하는 getHelper() 메쏘드는 다중 쓰레드 환경에서 다음과 같이 구현하면 간단하다. public synchronized Helper getHelper() { if (helper == null) { helper = new Helper(); } return helper; } 하지만 해당 객체를 생성할 때뿐만 아니라 매번 접근할 때마다 동기화 블럭을 거쳐야 하므로, 수행 성능을 개선하기 위해 먼저 객체가 있는지 여부를 동기화 블럭 밖에서 검사한 다음 없을 경우에만 동기화 블럭을 사용하여 객체를 생성하도록 한 것이 이중 검사 방식의 잠금이다. 이중 검사라는 이름은 synchronized 블럭 안에서 한번 더 검사를 한다는 의미에서 붙여진 이름이다. <리스트 6>에 나온 부분 코드를 보자. 언뜻 보기에는 확실한 방법으로 보인다. 아마도 이 방법을 사용한 개발자도 많으리라 생각된다. 하지만 자바 메모리 모델은 이것의 정상적인 수행을 보장하지 못한다. 먼저 helper = new Helper()라는 문장을 수행할 때 컴파일러의 최적화에 의해 Helper의 생성자를 수행하는 동안에 helper 필드에 객체를 대입하는 경우가 있을 수 있다. 즉 Helper라는 객체가 생성되는 과정은 먼저 메모리 힙에서 객체의 공간이 할당되고 기본 값들로 채워진 다음 생성자의 몸체 코드들을 수행하게 되는데 실제 몸체 코드가 수행되기 전에 helper 필드로 대입되는 순서 변경을 컴파일러가 시도할 수 있다. 자바 메모리 모델은 컴파일러의 최적화에 관련된 이러한 순서 변경을 허용한다. 또, 컴파일러가 변경하지 않은 경우에도 동시에 하나 이상의 인스트럭션을 수행할 수 있는 프로세서의 경우나 메모리 시스템에 따라서 이러한 순서가 변경될 수 있다.
이에 대한 해결책으로 제안되고 있는 것은 다음과 같은 방법들이 있다. 먼저 Helper 객체를 생성하는 부분은 별도의 클래스에서 static 필드로 선언하는 방법이다. 이렇게 되면 static 필드에 접근하려고 하는 순간에 해당 객체가 생성될 것이다. class HelperSingleton { static Helper singleton = new Helper(); } 다른 몇 가지 방법도 제안되고 있으나 ThreadLocal 등을 사용하는 방법은 구현 가능하나 성능 면에서 오히려 동기화 블럭을 바로 사용하는 getHelper() 버전보다 더 나쁘기 때문에 권장되지 않는다. 또 하나의 방법은 자바 2 SDK 1.5에 새로 추가된 방법이다. 즉 volatile 변수와 같은 개념을 객체 참조에까지 확장하는 java.util.concurrent.atomic 패키지의 AtomicReference 클래스를 활용하는 방법이다(참고로 사용된 코드는 자바 2 SDK 1.5 베타 2판이므로 정식 릴리즈에서는 API가 변경될 가능성도 있다).
SDK 1.5의 새로운 동기화 구조 동기화 구조와 더그 리 자바는 가상머신을 필요로 하고 또 가상머신을 부트스트랩하는 데 상당한 시간과 메모리 리소스가 소요되기 때문에 여러 개의 자바 프로세스를 사용하여 프로세스간 통신을 하는 프로그램을 작성하는 것은 많은 경우 피해야 한다. 이러한 자바의 특성은 쓰레드 기반의 프로그램 구조를 더욱 중요하게 만드는데, 쓰레드를 사용하여 여러 객체간의 통신이나 자원 공유가 필요할 경우 전체적인 쓰레드간 구조를 먼저 잘 정의하는 것이 불필요한, 혹은 잘못된 잠금 구조와 경쟁 조건에 대한 어려움을 더는 유일한 방법이다. 쓰레드 모델을 구현할 때 혹은 경쟁 조건과 동기화 문제를 해결하고자 할 때 검증된 동기화 구조를 활용하는 것은 효율적일 뿐 아니라 버그를 방지할 수 있고 전체 아키텍처를 개선하는 효과를 가져온다. 자바의 여러 가지 동기화 구조를 이야기할 때는 더그 리(Doug Lea)에 대한 소개를 빼놓을 수 없다. 더그 리는 자바의 아버지라고 불리는 제임스 고슬링(James Gosling)과 더불어 자바 명세를 정하는 JSR의 초기 시절에 개인 자격으로 투표권을 행사할 수 있었던 단 두 명 중 한 명으로, 현재는 JSR 166번에서 자신이 만든 공개 소스코드 동기화 관련 클래스들을 자바의 표준으로 SDK 1.5에 포함시키는 작업을 하고 있다. 그의 노력으로 SDK 1.5에는 훌륭한 쓰레드 동기화 구조 클래스들의 집합인 java.util.concurrent 패키지가 포함되었고, 이들 API에 대한 자바 가상머신 차원에서의 최적화 또한 진행되었다. 흔히 SDK 1.5를 이야기하면 몇 가지 언어 문법 차원의 변화와 메타정보 처리 기능(Annotations), 템플릿(Generics) 등을 떠올리지만 이 동기화 관련 패키지 또한 커다란 변화이고 또 자주 사용하게 될 것이다. java.util.concurrent 패키지 java.util.concurrent 관련 패키지에는 많이 사용되는 동기화 구조, 잠금, 큐, 쓰레드 풀, 그리고 동기화에 사용되는 새로운 시간 단위 클래스들이 정의되어 있다. 이들 중 자주 사용될 구조들에 대해 간단하게 소개하고자 한다. Executor와 Future Executor 인터페이스는 쓰레드를 실행시키는 새로운 방법을 정의하고 있다. Thread 클래스의 start() 메쏘드를 호출하는 대신 좀 더 직관적으로 Runnable을 실행시키거나 Callable을 실행시킨다. Callable은 Runnable과 유사하나 리턴값을 가질 수 있으며 예외를 던질 수 있다. Future 인터페이스는 비동기적으로 쓰레드를 수행하고 다른 일을 수행한 후 나중에 그 결과 값을 가져올 수 있는 구조이다. <리스트 8>에 나온 예제는 실제 사용하는 방법을 잠깐 보여준다. SDK 1.5의 Generics가 사용되어 코드가 조금 어색해보일 것이다. Executor 구현 객체를 만들어 주는 Executors 클래스의 팩토리 메쏘드를 사용해 ExecutorService 객체를 생성하고, Future 인터페이스 구현 클래스인 FutureTask 클래스를 사용하여 Future가 Callable을 수행하고 그 결과를 가지고 있도록 했다.
쓰레드 풀 쓰레드 풀은 서블릿 서버, EJB 서버 등의 구현에 종종 사용되는 구조이다. 주인/일꾼 모델(boss/worker model, master/slave model)에서 많이 사용되는데, 이 형태의 쓰레드 모델에서 주인 쓰레드는 쓰레드 풀에서 쉬고 있는 일꾼 쓰레드를 골라 작업을 넘겨준다. 쓰레드 풀 역시 Executors 클래스의 팩토리 메쏘드를 사용하여 다음과 같이 Executor처럼 사용할 수 있다. ExecutorService executor = Executors.newCachedThreadPool(); 지원하는 쓰레드 풀은 재사용되고 필요할 경우 생성하는 방식의 캐시 쓰레드 풀, 고정 크기 쓰레드 풀, 쓰레드 실행을 스케줄할 수 있는 스케줄링 쓰레드 풀 등이 있다. 큐 클래스 Collection 클래스의 하나로 Queue 인터페이스를 java.util 패키지에 포함시키면서 동기화 패키지에는 몇 가지 종류의 큐들이 지원된다. 큐는 가장 많이 사용되는 동기화 구조 중 하나로 용도에 따라 조금씩 다른 버전을 사용한다. 예를 들어 생산자/소비자 쓰레드 모델(producer/consumer model)에서 많이 사용되는 블로킹 큐 구조를 구현한 BlockingQueue 인터페이스가 있으며, 크기 제한 없는 넌블로킹 큐인 ConcurrentLinkedQueue 클래스 등이 있다. BlockingQueue 인터페이스를 구현한 여러 개의 블로킹 큐 구현 클래스들은 다른 컬렉션 구현 클래스와 마찬가지로 사용처에 따라 좀 더 적합한 알고리즘을 골라서 사용할 수 있다. Lock과 Condition Lock 인터페이스는 자바의 동기화 블럭 표현 방식인 synchronized 블럭 대신에 명시적인 잠금 획득과 잠금 해제를 사용하는 방식이다. C/C++에서 제공하는 잠금 방식과 유사한 방식으로 코드 차원에서 잠금을 반드시 풀어줘야 한다는 제약이 있지만 블럭 구조가 아닌 방식, 즉 필요에 따라 잠금 획득과 잠금 해제가 완전히 다른 메쏘드나 블럭에서 처리될 수도 있으며, 잠금을 획득할 때 tryLock()을 사용할 수 있다는 장점이 있다. Condition 인터페이스는 자바의 동기화 이벤트 표현 방식인 wait(), notify() 메쏘드에 대응하는 개념으로 wait(), notify() 메쏘드들이 대응하는 synchronized 블럭 안에서 동작하듯이 Condition 객체는 대응하는 Lock 객체를 통해 동작한다. Condition 객체를 사용할 때의 장점으로는 하나의 Lock 객체에서 여러 개의 Condition 객체를 사용할 수 있다는 점을 들 수 있다. 세마포어 클래스 세마포어(Semaphore) 역시 많이 사용되는 동기화 구조 중 하나이다. 세마포어는 내부적으로 숫자 값을 유지하고 있는데 이 값은 얼마든지 커질 수 있지만 0보다 작을 수는 없다. 세마포어는 acquire와 release 두 개의 연산을 지원하며, acquire시에는 숫자 값을 1 감소시키고, release시에는 숫자 값을 1 증가시키되 숫자 값이 0이 되면 acquire를 요청한 쓰레드가 무한히 기다리도록 하는 방식으로 동작한다. 이렇게 함으로써 결과적으로 동시에 접근하는 쓰레드의 갯수를 지정한 숫자 값으로 제한하게 된다. ReadWriteLock 클래스 프로그램에 따라 여러 개의 쓰레드들이 공유하는 데이터를 읽는 횟수가 쓰는 횟수보다 훨씬 많은 경우가 있다. 이런 경우 여러 개의 쓰레드가 동시에 읽을 수 있도록 허용하고 쓸 경우에는 배타적으로 접근을 막는 방식의 잠금 구조가 단순한 잠금 구조에 비해 훨씬 효율적일 수 있다. 즉, 빈번하게 일어나는 읽기의 경우에는 여러 개의 쓰레드들이 잠금이 필요 없이 접근할 수 있으므로 잠금의 오버헤드를 피할 수가 있다. 특히 읽는 동작이 긴 경우에는 더욱 효율적이다. 읽기/쓰기 잠금 구조에서 만약 쓰기 쓰레드가 예상한 비율보다 더 많이 접근할 경우 쓰기 쓰레드가 잠금을 아예 얻지 못할 수도 있다. 이런 경우를 흔히 기아 상태(starvation)라고 부른다. 읽기/쓰기 잠금 구조에서 잠금 다운그레이드 개념이 지원된다. 이것은 쓰기 잠금을 가진 쓰레드가 읽기 잠금을 얻은 다음, 쓰기 잠금을 풀어 결과적으로 읽기 잠금으로 다운그레이드하는 개념이다. 읽기 잠금을 가진 쓰레드는 절대 쓰기 잠금을 획득할 수 없다. 즉 쓰기 잠금으로 업그레이드할 수는 없다. CyclicBarrier 클래스 방벽 구조(Barrier)는 여러 쓰레드가 서로의 수행을 동기화하기 위해 기다리는 동기화 지점을 나타내는 구조이다. 서로 협업하는 쓰레드들이 모두 방벽 지점에 이를 때까지 기다렸다가 모두 도착하면 다음 단계로 넘어가는 방식으로 진행된다. 즉 마지막 쓰레드가 방벽 지점에 도착할 때까지 먼저 온 쓰레드는 기다리고 있다가 도착하는 순간 모두 다시 진행을 계속한다. 즉, 일정 개수의 쓰레드가 도달할 때까지 방벽이 각 쓰레드의 진행을 막고 있다가 일정 개수의 쓰레드가 도달하는 순간 도달한 쓰레드를 모두 방벽을 지나가도록 통과시키는 구조이다. 이 구조는 선원 모델(work crew model 혹은 divide and conquer model)을 구현하는 데 많이 사용된다. 선원 모델에서는 하나의 작업을 여러 조각의 부분 작업으로 나누어 여러 개의 쓰레드가 한 조각씩 동시에 수행하는 방식으로 작업을 수행한다. 각 쓰레드는 다른 쓰레드의 작업 진행 상태에 의존하지 않고 독자적으로 작업을 진행한다. 선원 모델의 예는 어떤 영역에 걸쳐 자료를 검색하는 작업이 있을 때 영역을 분리하여 각 영역별로 선원 쓰레드를 만들어 검색하는 것을 생각해볼 수 있다. 각 부분 영역을 맡고 있는 쓰레드들이 모두 작업을 완료하면 부분 작업 결과들을 통합하여 전체 작업 결과가 나온다. 일반적으로 선원 모델을 사용할 경우 각 선원 쓰레드별로 종료 시간이 다르므로 모든 선원 쓰레드가 종료한 후 각 결과물들을 종합하는 방식으로 진행하게 된다. CyclicBarrier 클래스는 방벽 구조를 잘 구현한 클래스인데 도달한 각 쓰레드는 CyclicBarrier 객체의 await() 메쏘드를 호출하고, 지정된 정원이 찰 때까지 블로킹된다. 정원이 차고 난 다음에는 CyclicBarrier 객체를 생성할 때 Runnable 객체가 지정한 경우 이 객체를 실행하여 결과물들을 종합하는 개념의 일을 할 수 있다. CyclicBarrier 객체는 이 Runnable을 수행한 후 블로킹됐던 모든 쓰레드를 풀어준다. CountDownLatch 클래스 CountDownLatch 클래스는 CyclicBarrier 클래스와 유사하게 해당 객체에 대해 await() 메쏘드를 호출하면 조건이 충족될 때까지 블로킹되지만 CyclicBarrier가 await()를 호출한 쓰레드의 갯수에 따라 블로킹을 풀어주는 반면, CountDownLatch는 countDown() 메쏘드가 호출되는 횟수에 따라 블로킹을 풀어주게 된다는 점이다. 또 CyclicBarrier 객체는 reset() 메쏘드를 제공해 다시 사용할 수 있지만 CountDownLatch 객체는 한번만 사용할 수 있다. Exchanger 클래스 Exchanger 클래스는 두 개의 쓰레드가 특정 지점에서 동일한 자료형의 데이터를 서로 교환할 수 있는 특별한 동기화 구조이다. 두 개의 쓰레드가 동일한 Exchanger 객체에 대해 exchange() 메쏘드를 호출하면 두 쓰레드가 모두 호출할 때까지 블로킹되었다가 서로의 값을 교환한 후 계속해서 쓰레드가 진행하게 된다. 쓰레드, 동기화, 데드락 얼마 전 데드락 문제 해결을 요청받아 소스코드를 살펴보니 문제의 원인은 동기화된 메쏘드의 리턴 값을 비교하는 순간에 임시 변수로 저장되는 문제였다. 즉 다음 소스코드에서 getValue() 메쏘드는 동기화되어 있지만 그 결과 값을 0과 비교하기 위해 해당 값이 보이지 않는 임시 변수에 저장되고 0과 비교된다. 이 문제는 1개의 CPU를 가진 곳에서는 데드락이 검출되지 않다가 2개의 CPU를 가진 서버에서는 다행히도 100번에 한두 번 간격으로 주기적으로 발생했다. public synchronized int getValue() { return value; } ... void someOtherClassMethod() { synchronized(other) { if (x.getValue() > 0) { ... } else { ... } } } 이 문제는 비교하는 소스코드 자체를 해당 객체의 동기화 블럭 안으로 옮기는 리팩토링을 통해 해결되었다. public synchronized boolean isPositive() { return value > 0; } ... void someOtherClassMethod() { synchronized(other) { if (x.isPositive()) { ... } else { ... } } } 자바 메모리 모델은 synchronized 블럭과 volatile 변수에 대해 다중 쓰레드 환경에서 특별한 의미를 부여하였고, 그렇지 않은 경우는 다양한 최적화의 가능성을 열어놓고 있다. 데드락 상황에서 중요한 것은 무엇보다도 데드락 시나리오의 논리적 재구성이다. 이것은 다른 버그들에 비해 순수하게 논리적으로 구성해야 하는 부분이 많기 때문에 어렵게 느껴지기도 한다. 하지만 어렵다고 다른 해결 방법이 있는 것이 아니라면, 또 다중 쓰레드 환경을 필요로 한다면 침착하게 분석하는 자세가 필요하다. 어쩔 수 없이 수많은 잠금이 필요한 경우가 있다. 이러한 잠금 구조를 개선하고 더 나은 수행 성능을 보장하려면 좀 더 적합한 동기화 구조가 없는지 한번 살펴보기 바란다. 많은 경우 자바 2 SDK 1.5의 동기화 구조들을 적용할 수 있을 것이다. 이에 따라 동기화 구조가 간결해지고 버그의 가능성을 낮춰 줄 것이다. SDK 1.4에 당장 적용할 수 있는 동기화 구조를 찾는다면 이 패키지의 기존 버전인 더그 리의 util.concurrent 패키지를 사용할 수 있다. java.util.concurrent 패키지에 대해 충분한 소스코드 수준의 소개를 하고 싶었지만 개괄적인 소개에 그쳐 아쉽다. 사용 방법은 어렵지 않으므로 해당하는 동기화 구조가 어떤 일을 하는지, 어떤 상황에 적합한지 충분히 이해한다면 쉽게 적용할 수 있으리라 믿는다.@ |


'Java' 카테고리의 다른 글
| Runtime.exec() (1) | 2006.07.08 |
|---|---|
| JVM options (0) | 2006.06.23 |
| HP-UX 에서 JNI 테스트 (0) | 2006.05.12 |