초보자를 위한 리눅스 커널의 메모리 관리
등록: 한빛미디어(주)(2005-08-05 11:51:34)
Published onHanbit Network(http://network.hanbitbook.co.kr/)
저자:한동훈(traxacun)
이 글은 리눅스 커널을 처음 공부하는 분들에게만 적합하며, 이미 잘 알고 계시는 분들에게는 적합하지 않을 수도 있습니다. 본 기사에서는 다음 주제들을 다룰 것입니다.
1. Memory Model
2. i386 CPU에서의 메모리 관리
3. 리눅서 커널에서의 메모리 관리
4. 커널에서의 코드
메모리 모델
예를 들어서, 1M 메모리를 가진 시스템이 있습니다. 이 시스템에서 메모리를 300k 사용하는 프로그램 A가 있고, 500k를 사용하는 프로그램 B가 있습니다. 그런데, 프로그램 A는 데이터가 많아질수록 더 많은 메모리를 사용하게 되어 있어서 600k의 메모리를 사용하게 되었습니다. 이런 경우에는 메모리가 프로그램 A와 B가 서로 충돌하게 되어 더 이상 프로그램을 실행할 수 없게 될 것입니다. 프로그램을 작성하면서 계산기 프로그램이 내 프로그램의 메모리 영역을 침범하면 안되는데라고 고민하면서 프로그램을 작성하지는 않을 것입니다. 이와 같이 다양한 프로그램들이 메모리를 사용할 수 있게 하기 위해 OS는 메모리를 관리합니다.
메모리 모델의 종류
메모리를 관리하는 방법은 세그먼트(Segment) 기법과 페이징(Paging) 기법이 있습니다. 우리가 흔히 보는 책은 페이지를 매기는 방법이 두 가지가 있습니다. 예를 들어, 1,000 페이지짜리 책이 있을 때 페이지를 1번부터 1,000번까지 모두 매겨놓은 책이 있는가하면, 책을 챕터별로 나누어서 각 챕터에서 몇번째 페이지라고 표기하는 방법이 있습니다. 선형적으로 일괄되게 페이지를 매기는 방법을 페이징이라 하고, 각 챕터별로 책을 나누고, 챕터에서 몇번째 페이지(Offset)라고 나누어 관리하는 방법을 세그먼트라고 합니다.
현대 운영체제는 정확하게 세그먼트와 페이징으로 나누어 관리하기 보다는 이 두가지를 적절하게 혼합된 형태를 사용합니다.
여기까지는 메모리를 관리하는 방법을 이론적으로 나눈 것이고, CPU에서 메모리를 관리하는 것은 다릅니다. 즉, OS에서 메모리를 관리하는 방법은 OS를 제작하는 사람이 마음대로 정할 수 있는 것이지만 실제로 CPU와 데이터를 주고 받을 때는 CPU에 맞춰서 데이터를 주고 받아야 합니다. 우리가 사용하는 x86 CPU는 리얼 모드(Real Mode)와 보호 모드(Protected Mode)를 사용합니다. 리얼 모드는 예전에 도스(DOS)를 사용하던 시절에 사용하던 모드로 1M 까지의 메모리를 사용할 수 있습니다. 보호 모드에서는 메모리를 0-4G까지 사용할 수 있습니다. 요즘에는 모두들 512M 이상의 램을 장착해서 사용하는 것이 보편적이니 리얼 모드는 몰라도 되지 않아라고 생각할 겁니다. 그러나, 시스템이 처음 전원이 들어가고, 부팅이 될 때는 리얼 모드로 실행되고, 그 이후에 보호 모드로 넘어가게 됩니다. 그렇게 때문에 커널을 학습하는 사람들은 CPU에서 메모리를 관리하는 방법이 리얼 모드일때와 보호 모드일 때 다르다는 것을 알아야 합니다. 이에 대해서는 뒤에서 보다 자세히 설명하도록 하겠습니다.
커널의 메모리 모델
리눅스 커널이 생각하는 메모리 모델은 크게 두 가지 뿐입니다. 하나는 물리 메모리(Physical Memory)이고, 다른 하나는 가상 메모리(Virtual Memory)입니다.
많은 분들이 들어보았을 이야기는 프로세스 하나당 4GB까지의 메모리 공간을 가진다는 것입니다. 즉, 스타크래프트도 4GB의 메모리 공간을 사용한다고 생각하고, 인터넷 익스플로러도 4GB의 메모리 공간을 사용한다고 생각합니다. 잠깐만요! 저는 PC에 램이 512M 밖에 없는데요? 라고 생각할 수 있습니다.
잠시 생각하면 알 수 있는 것처럼 모든 프로그램은 4G라는 메모리를 모두 사용하는 것이 아닙니다. 실제로는 매우 작은 일부만 사용할 뿐입니다. 그러니 사용하지 않는 부분은 무시하고, 사용하는 부분만 메모리에 갖고 있으면 됩니다.
프로세스는 4G의 공간이 전부 자기것이라고 생각하고, OS는 프로세스가 실제로 사용하는 부분만 실제 메모리에 올려놓으면 됩니다. 즉, 가상 공간과 실제 메모리 공간을 연결할 수 있는 변환 테이블이 하나 있으면 되겠네요!
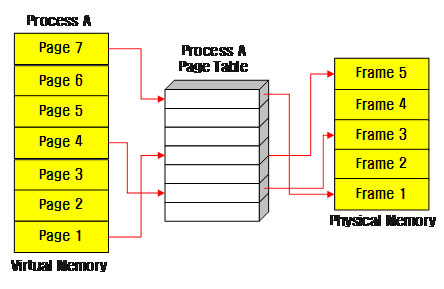
그림1. 프로세스 A의 가상 공간과 실제 메모리
그림에서 볼 수 있는 것처럼 프로세스 A는 페이지 1, 4, 7번을 사용하고 있습니다. 그리고 이들 각각은 실제 메모리 프레임 5, 3, 1에 저장되어 있습니다. 이와 같은 방법을 사용하기 때문에 각 프로세스는 각자가 4G의 공간을 사용하고 있다고 생각하고, 다른 프로그램이 사용하는 메모리 공간에 대해 염려하지 않고 프로그램을 작성할 수 있는 것입니다.
x86 아키텍처의 메모리 모델
CPU는 연산을 위해 메모리와 데이터를 주고 받습니다. 즉, CPU가 메모리를 어떻게 이용하는지 알고 있어야합니다. CPU마다 메모리를 이용하는 방법은 각기 다르지만, 여기서는 가장 흔하게 사용되는 x86 CPU에 대해서 살펴볼 것입니다.
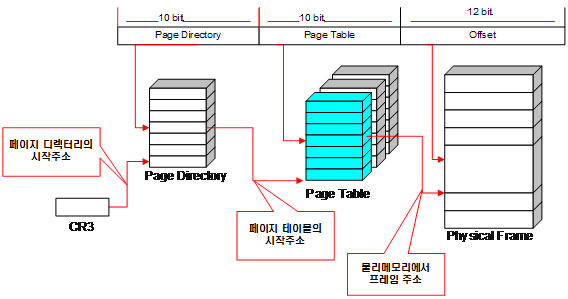
그림2. x86 CPU의 메모리 모델
x86 CPU는 32bit 환경이라고 얘기합니다. 즉, 메모리도 32bit에 해당하는 2의 32승 = 4G까지 사용할 수 있습니다. 각 페이지를 4096 바이트로 나누어서 관리하고 있습니다. 즉, 2^12 = 4096입니다. 따라서, 12 비트는 각 페이지의 위치를 가리키기 위해서 사용됩니다.
4G의 공간을 4096 페이지 크기로 나누면 1,048,576이고, 이 숫자의 의미는 4G의 메모리 공간을 4k 크기의 페이지로 나누어 관리하기 위해서는 페이지 테이블이 1,048,576개나 필요하다는 의미가 됩니다. 즉, 2^20 = 1,048,576이고, 1개의 PTE는 4 바이트이기 때문에 페이지 테이블이 차지하는 메모리의 크기는 1,048,576 * 4 = 4M가 됩니다. 즉, 하나의 프로세스가 4G의 메모리 공간을 관리하는 페이지 테이블을 유지하기 위해서는 4M가 필요하다는 것입니다. 프로세스 1개 생성에 4M를 무조건 사용한다는 것은 꽤나 큰 낭비입니다.
그렇다면, 20비트를 한꺼번에 이용하는 대신에 10비트씩 나누어서 사용하면 어떨까요?
2의 10승은 1024개이고, 한 항목은 4 바이트를 차지하므로 1024 * 4 = 4096 = 4k를 사용하게 되고, 4k는 메모리에서 1 프레임만 차지합니다.
그래서 그림2와 같이 페이지 디렉토리에 10비트, 페이지 테이블에 10비트를 사용합니다.
간단하게 C언어의 정의대로 적어보면 다음과 같습니다.
첫번째는 20비트를 사용했을 때의 배열 선언이고, 두번째는 10비트씩 나누어서 디렉토리, 테이블로 사용할 때의 선언입니다. 물론, 리눅스 커널의 선언이 이렇게 되어 있다는 것은 아닙니다.
첫번째 배열 선언이 차지하는 크기를 생각해보면 4M이고, 두번째 배열 선언이 차지하는 크기는 8k입니다.
0xC1234567이라는 논리 주소가 주어졌을 때 실제로 CPU에서 어떻게 실제 메모리를 찾아가는지 살펴보겠습니다.

그림3. 논리 주소
0xC1234567이라는 16 진수를 2진수로 풀어서 쓰면 11000001001000110100010101100111이며, 이를 각각 10, 10, 12 비트씩 끊으면 위 그림과 같다.
그림2에 나온 것처럼 CPU에는 CR3 레지스터가 있으며, 이 레지스터는 메모리 관리를 위한 페이지의 출발지 정보를 갖고 있다. 따라서 CR3 레지스터의 값을 읽어서 페이지 디렉토리가 시작하는 위치를 알아내고, 상위 10비트 1100 0001 00번째에 해당하는 위치로 디렉토리에서 이동하는 것이다. 16진수로는 0x304이며, 10진수로는 772가 된다. 772라는 의미는 페이지 디렉토리의 1024개 중에서 772번째 항목을 의미한다. 실제로는 773번째지만, PC에서는 값을 0부터 세어나가기 때문에 혼동하지 않게 0번째, 1번째, 2번째, 처럼 772번째라고 하겠다. 한 항목이 4바이트이므로 772 * 4 = 3088 로 이동해야한다. 여기서 읽어들인 값은 다시 페이지 테이블의 시작주소를 가리킨다. 페이지 테이블에 저장된 값 1000 1101 00 = 0x234 = 567이므로, 567번째 항목으로 이동해야 한다. 마찬가지로 각 항목이 4바이트 이므로 567 * 4 = 2256 위치로 이동해서 물리 프레임의 메모리 주소를 알아낸다. 마지막 오프셋은 여기서 알아낸 메모리 주소 값에 대한 상대위치를 나타내는 값이기 때문에 값을 단순히 더하기만 하면 된다.
2256위치에서 읽어들인 값이 0x40000이고, 오프셋의 값이 1383이면 실제 메모리 주소의 위치는 0x41383이 된다.
리눅스 커널의 메모리 모델
리눅스 커널은 64비트 선형 주소를 사용한다. 커널에서 64비트 주소를 사용하는 이유는 Alpha CPU와 같이 64비트 주소를 사용하는 시스템을 지원하기 위해서이다.
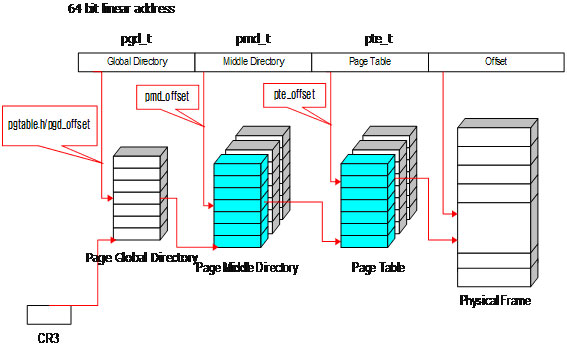
그림4. 리눅스 커널의 메모리 모델
리눅서 커널도 x86 CPU와 마찬가지로 메모리 관리의 효율성을 위해 페이지 디렉토리를 글로벌 디렉토리와 미들 디렉토리로 나누어서 관리한다. 즉, x86 CPU에서 2단계 페이징을 사용한다면 커널에서는 3단계 페이징을 사용하는 것이 차이점이다.
글로벌 디렉토리는 pgd_t, 미들 디렉토리는 pmd_t, 페이지 테이블은 pte_t로 나타내며, 오프셋은 상대위치이기 때문에 따로 나타낼 필요는 없다.
x86에서는 2단계를 사용하고, 리눅스 커널에서는 3단계를 사용한다면 커널은 x86 환경에서는 어떻게 해야할까? x86 CPU를 지원하기 위해 별도로 2단계 페이징을 만들어야 할까? 라고 생각할 수 있는데 실제로 커널은 위 구조를 그대로 유지하면서 2단계 페이징을 지원하는 방법을 택했다. 즉, 미들 디렉터리를 1개만 사용하는 것이다. 이렇게 하면 커널의 코드를 크게 변경하지 않으면서 64비트 환경과 32비트 환경을 쉽게 지원할 수 있다.
각 시스템마다 메모리 관리를 위해 사용하는 비트수는 다르기 때문에 위 그림에서 몇 비트씩 사용하는지 명시하지 않았다. 물론, 특정 플랫폼마다의 비트수를 적는다면 적을 수 있지만 여기서는 그렇게 하지 않았다.
x86 CPU와 커널에서 메모리를 찾는 방법을 보면 먼저 CR3 레지스터에서 글로벌 디렉터리의 시작 주소를 알아내고, 글로벌 디렉토리에서 몇번째 위치인지 알아낸다고 했다. 여기에 쓰이는 함수가 pgd_offset()이다. 마찬가지로 미들 디렉토리에서의 위치를 알아내는 것은 pmd_offset, 페이지 테이블에서의 위치를 알아내는 것은 pte_offset이다. pgd_offset, pmd_offset, pte_offset은 모두 2개의 인자를 갖는다.
pgd_offset(mm, address)인데 mm은 메모리 관리를 위한 구조로 각 프로세스마다 1개씩 갖고 있다. 즉, 페이지 글로벌 디렉토리의 시작 위치가 되며, address는 페이지 글로벌 디렉터리에서 몇 번째 위치라는 것을 나타낸다. 마찬가지로 pmd_offset의 첫번째 인자는 페이지 미들 디렉토리의 시작위치를, 두번째 인자는 페이지 미들디렉토리의 몇번째 페이지를 인자로 받는다. pte_offset도 동일하다. Redhat 9에 포함된 커널 2.4.20-8 버전에서는 pte_offset 대신에 pte_offset_kernel을 사용하면 된다. 상위 버전의 커널에서는 pte_offset으로 이용할 수 있다.
이들 함수(정확히는 매크로)를 이용하면 프로세스가 실제로 이용하고 있는 물리 메모리를 알아낼 수 있다. 이들 매크로는 arch/asm-i386/pgtable.h, pgtable-3level.h에서 찾아볼 수 있다. 참고로 실제로 존재하지 않는 페이지 글로벌 디렉토리, 미들 디렉토리 등을 액세스하려하면 중대한 커널 오류가 발생할 수 있다. 따라서, 페이지를 액세스하기 전에 각각 pgd_present, pmd_present, pte_present를 사용해서 실제 페이지가 있는지 확인하고 사용해야 한다.
프로세스에서 바라본 메모리
프로세스마다 4G의 가상 공간을 사용한다고 얘기했다. 그리고, 프로세스마다 메모리 관리를 하기 위해 페이지 글로벌 디렉토리, 페이지 테이블과 같은 구조를 갖고 있다고 했다. 프로세스를 나타내는 구조체는 task_struct이며, 여기에는 메모리 구조를 나타내는 mm_struct mm이 있다. mm은 메모리 관리를 위한 구조체이며, pgd_t* pgd는 페이지 글로벌 디렉토리의 시작 위치를 가리킨다. 즉, pgd가 가리키는 값과 CR3 레지스터가 가리키는 값이 같다. 그 이후부터는 앞에서 설명한 것처럼 각 페이지별로 주소를 찾아서 실제 메모리상의 프레임을 찾아간다.
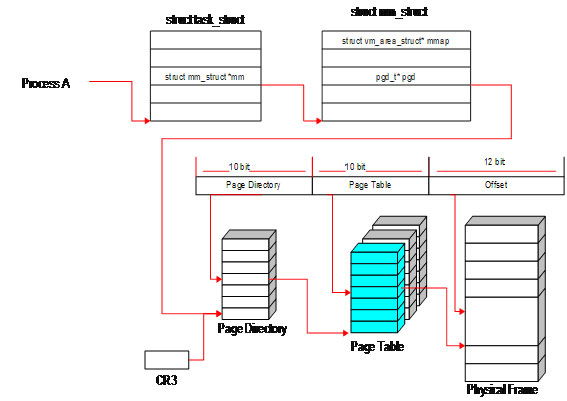
그림5. 프로세스에서 바라본 메모리
이를 자세하게 표현하면 그림6과 같습니다. 각각의 프로세스는 task_struct 구조체로 표현되며, 이를 간단히 PCB(Process Context Block, 컨텍스트 문맥)이라고 이야기한다. 커널에는 프로세스 ID로 해당 PCB를 찾아내는 함수가 있는데 이 함수가 find_task_by_pid(pid)이다. 이 함수는 프로세스 ID, PID를 인자로 넘겨 받으면 task_struct에 대한 것을 반환해준다.
물론, 현재 프로세스는 current로 접근할 수 있지만, 다른 프로세스에 대한 task_struct를 얻어오려면 find_task_by_pid를 사용해야 한다. task_struct에는 mm이 있고, 이 mm이 mm_sturct 자료구조를 가리킨다.
그림1을 생각해보면 프로세스는 연속적인 가상 메모리를 할당 받는 것도 아니라 여러 개의 가상 메모리 블록을 할당받는다. 즉, 연속적으로 할당 받을 수도 있고, 따로따로 할당 받을 수도 있다는 얘기다. 이를 위해서 mm_struct에 보면 각각의 가상 메모리 블록을 관리하는 vm_area_struct 구조체가 있다. 그리고 vm_area_struct에는 각각 vm_start와 vm_end가 있는데 이는 가상 메모리 공간에서의 시작 위치와 마지막 위치를 가리킨다. 또한 vm_area_sturct* vm_next는 자신과 같은 형태의 구조체를 다시 가리키고 있는데, 이는 다른 가상 메모리 블록을 가리킨다. 즉, 단일 연결 리스트(Singly Linked List)로 연결되어 있다. vm_next를 따라 프로세스가 사용하는 전체 가상 메모리 공간을 알아낼 수 있다. 만약, vm_next가 NULL인지 아닌지를 알아내면 가상 메모리 블록의 끝을 알아낼 수 있다.
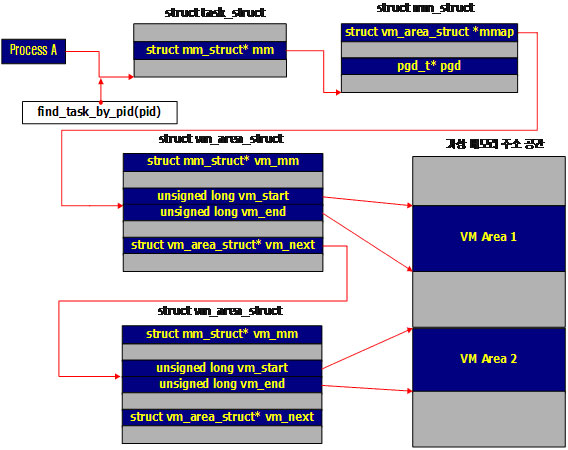
그림6. 프로세스에서 바라본 메모리 관리
마지막으로 task_struct에는 mm_struct로 선언된 변수가 두 가지가 있다. 하나는 mm이고, 다른 하나는 active_mm이다. mm은 프로세스가 사용하는 메모리 공간을 나타내고, active_mm은 CPU에 의해 현재 제어중인 주소공간을 가리킨다. 프로세스 A에게 있어서 mm과 active_mm은 같다. 즉, A->mm == A->active_mm이다. 그러나, 커널 스레드에서는 mm은 NULL이며, 커널 스레드가 사용중인 메모리는 active_mm으로 표현된다.
Linux 커널의 아버지인 Linus는 메모리 공간을 실주소공간(Real Address Spaces)과 익명주소공간(Anonymous Address Spaces)로 나눈다. 사용자 프로세스가 사용하는 주소 공간을 실주소공간아리하고, 커널 스레드가 사용하는 공간을 익명주소공간이라 하는 것이다.
모든 커널 스레드는 익명주소공간을 사용하며, 사용자 프로세스가 사용하는 실주소공간에 대해서는 관여하지 않는다.
foo라는 프로세스 A를 실행한다고 하자. 이 경우 A->mm == A->active_mm = foo일 것이다. 이때 커널 스레드 B에 의해 선점당한 경우 B->mm = NULL이지만, A->active_mm = foo를 여전히 가리키게 된다. 즉, 커널 스레드는 실주소공간을 신경쓰지 않지만, 작업 A가 다시 로드되었을 때 mm을 다시 로드하지 않기 위해 active_mm을 사용하는 것이다.
스왑
실제 메모리 사용량보다 더 큰 메모리가 필요한 프로그램을 실행할 수 있는 것은 가상 메모리 덕분이다. 앞에서는 가상 메모리에 대해서 살펴보았는데, 사용중이지 않은 부분은 스왑으로 저장해서 메모리에 여유공간을 확보하는 것이 스왑의 역할이다.
앞의 그림5에서 살펴본 것처럼 스왑을 한다는 것은 실제 메모리의 프레임을 디스크로 저장하는 것을 의미한다. 실제 메모리 프레임을 찾기 위해서는 페이지 테이블의 위치를 알아야하고, 페이지 테이블의 위치를 알기 위해서는 페이지 미들 디렉토리의 위치를 알아야한다. 마찬가지로, 페이지 미들 디렉토리의 위치를 알기 위해서는 페이지 글로벌 디렉토리의 위치를 알아야 한다. 이들 프로세스는 가상 메모리로 관리되고 있으니 가상 메모리 구조를 찾아봐야하고, 다시 실제 메모리 공간도 찾아봐야 한다. 즉, swap_out 함수는 이러한 순서들을 찾아가며 실제 메모리 프레임을 찾아가는 역할을 하고, 메모리 프레임을 디스크에 저장하는 것은 try_to_swap_out 함수의 역할이다.
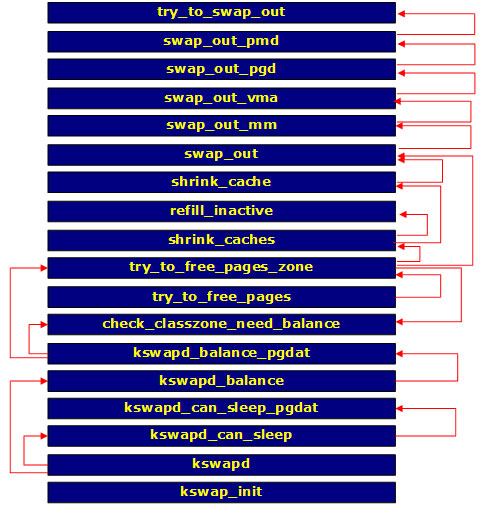
그림7. 스왑의 흐름
kswapd 함수는 daemonize 함수를 호출해서 자신을 데몬으로 등록시키고, 무한 루프를 돌면서 kwapd_can_sleep 함수를 호출한다. 이 함수는 지금 스왑 작업을 해도 되는지 아닌지를 판별하며, 이를 판별하기 위해서는 다시 kswapd_can_sleep_pgdat를 호출해서 페이지 글로벌 디렉토리에서 스왑이 필요한 페이지가 있는지 없는지를 판별한다. 스왑이 필요한 페이지가 하나라도 있으면 kswapd_balance를 호출한다. kwapd_balance는 메모리의 균형을 맞춰준다. 마찬가지로 이 함수도 kswapd_balance_pgdat를 호출하여 페이지 글로벌 디렉토리를 확인한다. try_to_free_pages 함수에서 try_to_free_pages_zone을 호출해서 사용할 수 있는 페이지 영역을 찾아보고, 사용할 수 있는 페이지가 부족한 경우에는 필요한 페이지를 확보하기 위해 shrink_caches를 호출한다. shrink_caches는 캐시들을 돌아다니며 비울 수 있는 캐시인지 판별하기 위해 shrink_cache 함수를 사용한다.
전체적인 흐름은 이렇게 되어 있으며, 각 프로세스에서 사용중인 스왑 공간은 task_struct의 swap_address로 알 수 있다.
스왑 정책
커널의 스왑 정책에서 사용할 수 있는 방법은 여러가지가 있지만, 리눅스 커널에서는 LRU(Least Recently Used) 정책을 사용한다고 알려져 있다. LRU는 가장 적게 사용된 페이지를 스왑으로 대체시키는 것이다.
메모리 페이지를 LRU 정책에 따라 스왑시키려면 해당 메모리 페이지가 액세스 된 적이 있는지 알아낼 수 있는 방법이 있어야 한다. 각 페이지가 액세스 된 시간을 기록해서, ‘아, 이 페이지는 1시간 전에 액세스했고, 이 페이지는 5분전에 액세스했네’라는 사실을 이용할 수도 있을 것이다. 단, 이렇게 한다면 액세스 될 때마다 시간을 기록하고, 각 페이지의 시간을 기록하고 유지하는 것만으로도 굉장히 높은 작업부하가 걸릴 것이라고 예상할 수 있을 것이다. 이런 스왑 정책은 OS가 단독으로 하기엔 어려운 부분이다. CPU에서는 이를 위해 액세스 비트(Access Bit)를 제공한다. 이 비트는 이 페이지가 접근된 적이 없으면 0, 있으면 1로 설정된다. 그림8에서 A가 액세스 비트를 나타낸다. 액세스 비트는 페이지에 접근할 때 CPU에서 자동으로 1로 설정하지만, CPU가 이를 다시 0으로 설정할 수는 없다. 0으로 설정할 수 있는 것은 오직 커널 뿐이다.
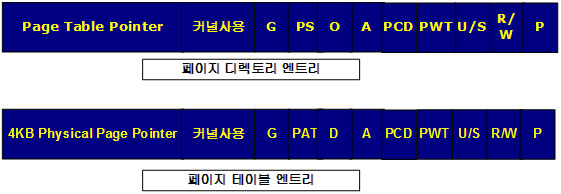
그림8. 페이지 엔트리
U/S는 사용자 프로세스가 접근할 수 있으면 1이고, 커널만 접근할 수 있으면 0으로 설정된다. R/W는 0이면 읽기만 가능하고, 1이면 읽기/쓰기가 모두 가능하다. P는 Present Bit라는 것으로 페이지가 메모리상에 존재하는지를 나타낸다. 즉, 페이지가 디스크로 스왑 되었으면 0이 된다. 프로세스가 이 페이지를 접근하려하면 P 비트가 0이기 때문에 페이지 폴트 인터럽트 #14가 발생하고, 디스크에서 다시 메모리로 이 페이지를 읽어들이고, P 비트를 1로 설정하게 된다.
메모리 관리와 관련된 부분은 OS가 독단으로 결정할 수 있는 것이 아니며, CPU와 OS가 서로 조화를 이루어가며 관리하는 부분이다.
코드로 보는 리눅스
8086 시스템은 과거에 20개의 어드레스 핀을 가진 16비트 시스템이었다. 즉, 2^20 = 1M까지 사용할 수 있는 시스템이었다. 이 의미는 1M 이상의 메모리를 사용할 수 없다는 것이다. 1M + 1번째를 접근하려 하면 1번째로 접근하게 된다. 이는 마치 프로그래밍 언어에서 만나는 정수 오버플로우와 같다. 1M + 1 = 1로 만들려면 어떻게 하면 될까? 2^20은 16진수로 0x100000이고, 2진수로는 100000000000000000000이다. 1M를 넘어가는 비트가 공교롭게도 가장 맨 앞의 비트이다. 즉, 맨 앞의 1을 0으로 만들어 주기만 하면 된다. 11111111111111111111 + 1을 하면 100000000000000000000이 되어야 하는데 20번째 비트를 0으로 만들면 결과 값은 0이 된다. +2를 하면 결과값은 1이 될 것이다.
이를 위해 8086 시스템에서는 20번째 핀을 키보드 인터럽트 핸들러인 8042와 AND 게이트로 연결해 놓았다. 20번째 핀이 켜지지 않으면 사용자는 항상 저 주소를 이용할 수 없다.
펜티엄 4에서 DOS용 응용 프로그램을 실행할 수 있다는 의미는 하위 호환성이 좋다는 의미이기도 하지만, 위와 같은 단점도 고스란히 물려받았다는 의미가 된다.
요즘과 같이 512M 램을 사용하는데, 저걸 알아서 뭐해요? 라고 되물을수도 있다. 그러나 A20을 켜주지 않으면 20번째 비트가 항상 0이 되기 때문에 1M = 0이 되고, 3M = 0이 된다. 즉, 1M에 해당하는 메모리 주소를 CPU가 액세스하려하면 0번째를 가리키게 된다. 사용자는 1, 3, 5, 7…과 같이 홀수번째 메모리를 전혀 사용할 수 없게 된다. 그렇게 때문에 부팅 과정에서 CPU가 리얼 모드에서 보호 모드로 넘어가기전에 반드시 A20 게이트를 켜야한다.
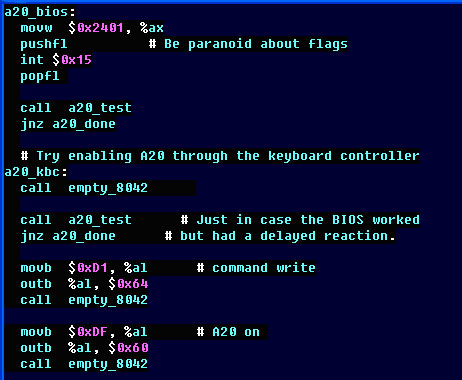
리눅스 커널의 소스 코드를 보면 그런 부분이 있다. movb $0xDF, %al이 있고, 옆에는 주석으로 A20 게이트를 켠다고 되어 있다. 이 부분의 값은 몰라도 된다. 저것은 CPU 매뉴얼에 있는 특정한 명령어인 것이다.
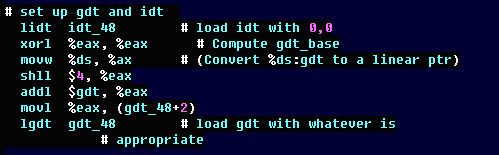
여기서는 lgdt gdt_48을 볼 수 있다. lgdt 명령어는 전체 커널 소스에서 단 한번만 사용된다. CPU는 리얼 모드에서 보호 모드로 넘어가기전에 글로벌 디스크립터(Global Descriptor)를 작성해야 한다. 즉, 4G에 해당하는 메모리를 어떻게 사용하겠는가를 설계하는 명세서와 같은 역할을 한다. 코드 세그먼트 디스크립터, 데이터 세그먼트 디스크립터, 비디오 세그먼트 디스크립터등을 지정할 수 있다. gdt_48은 명령어가 아니라 이러한 디스크립터를 적어놓은 곳으로 C언어의 struct와 같은 것이다.
리얼 모드에서 보호 모드로 넘어가는 순서는 1. 디스크립터를 정의한다. 2. lgdt 명령어로 디스크립터를 로드하고 보호모드로 전환한다. 이다.
CPU에는 명령어를 실행하는 부분이 3가지로 나누어져 있다. 첫번째는 명령어를 읽어들이는 부분, 두번째는 명령어를 해석하는 부분, 세번째는 명령어를 실행하는 부분이다.
즉, lgdt 명령어를 실행하게 되는 순간에 읽기 유닛, 해석 유닛에 이미 2개의 명령어가 들어가 있다. 보호모드로 전환된 다음에 리얼 모드에서 들어가 있던 명령어가 실행되면 안되니까 최소한 읽기, 해석 유닛의 명령을 무시하기 위해 두 스텝을 쉬어줄 필요가 있다. 따라서, lgdt 명령어를 실행한 다음에 어셈블리로 nop(No Operation: 아무일도 하지마!)를 2번 실행해주는 것이 관례다. 그런데, 커널 소스에선 nop 대신에 call delay를 사용하는 것 같다고 나름대로 추측할 수 있었다. nop 명령어를 커널에선 사용하지 않는다.
다음으로 첫번째 줄을 보면 lidt 명령이 있다. 이것은 인터럽트 디스크립터를 로드한다. 즉, Devide By Zero(인터럽터 0번)이라든가, 페이지 폴트(인터럽터 14번) 같은 인터럽트가 발생했을 때 이를 처리할 루틴의 위치를 지정하는 부분이 idt_48이고, lidt는 이를 메모리에 로드해주는 것이다.
굳이 이렇게 GDT를 꺼내든 이유는 <<리눅스 커널의 이해>>의 2장 메모리 관리 부분의 처음 1/2 정도가 전부 이 GDT 구조를 설명하는데 할애되어 있다고 느꼈기 때문이다. 책만 펼치면 잠이 쏟아질 만큼 졸린데, 이는 어셈블리와 CPU 구조에 대한 이해조차 없이는 책을 이해하기 어렵기 때문이라 생각했다. 즉, 내공이 부족한 내가 보기엔 어려운 책이다.
이들 어셈블리 코드는 arch/i386/boot에 있으며, 비디오 디스크립터는 video.S에 정의되어 있다.
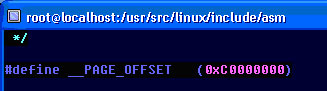
위 코드처럼 0xC0000000가 3G 영역을 가리킨다. 커널이 3G위의 영역을 사용한다는데 실제로 그 값이 있는지 확인해 본 부분이다.
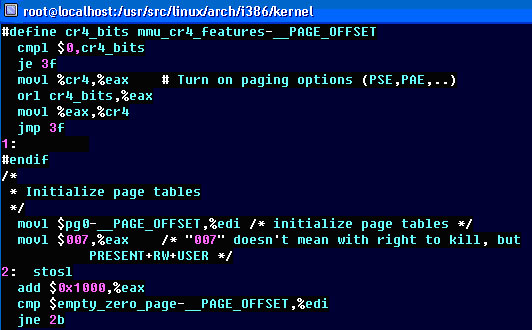
여기서는 앞에 CR4 레지스터가 보인다. CPU에는 CR0-CR4까지의 레지스터가 있다. 이중에서 CR3는 페이지 글로벌 디렉토리의 위치를 가리키며, CR4 레지스터는 PAE 확장을 사용할 것인가를 설정한다. 펜티엄 프로 이후에는 어드레스 핀이 4개가 더 추가되어서 4G가 아니라 64G까지 사용할 수 있게 해준다. 따라서, 이 값이 설정된 경우에 CR4 비트를 1로 설정해서 PAE 확장을 사용하게 설정해 주는 부분이다.
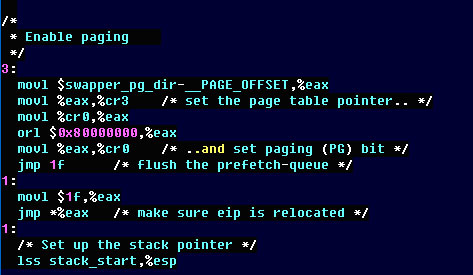
movl %eax, %cr3에서 페이지 테이블이 시작하는 위치를 CR3 레지스터에 저장하고 있다.(GAS, GNU Assembler는 AT&T 스타일을 따르고 있어서 어셈블리 명령어 인자 위치가 서로 반대다. mov a, b는 B의 값을 A에 넣는다이지만 AT&T 스타일에서는 A의 값을 B에 넣는다가 된다)
마치며
아직은 커널을 잘 알지 못하고 커널을 공부하는 입장에서 준비된 글입니다. 국내에 나와있는 다양한 커널 책들을 많이 참고했습니다. 아직 다루지 못한 부분들이 많습니다. 커널 소스에 대한 세세한 설명보다는 커널의 전체적인 흐름을 다루는 것이 세미나에는 더 적합하다고 판단해서 전체적인 흐름을 다루는데 중점을 두었습니다. kmalloc과 vmalloc의 차이점을 다루는 것 보다는 전체적인 흐름이 더 중요하다고 생각했습니다. 흐름에 대한 이해를 바탕으로 소스 코드를 살펴보는 것이 이해에 더 도움이 된다고 생각합니다.
레퍼런스
각각의 책마다 같은 부분을 보아도 설명이나 보여주는 부분이 다릅니다. 결국, 저자가 커널을 바라보는 방식에 대해 생각해보는 기회도 되고, 책을 가이드삼아 커널을 직접 찾아보며 전체를 바라볼 수 있는 안목을 기르는 것은 자신의 몫이라 생각됩니다. 주로 리눅스 커널 프로그래밍을 많이 참고했으며, 리눅스 커널 심층 분석은 커널 API 이해에 많은 도움이 되었습니다. Operating System Concepts는 운영체제가 시스템을 관리하는 다양한 방법과 알고리즘에 대한 해설이 중심이고 이를 토대로 리눅스 커널이 채택한 방법을 살펴보는 데 좋은 참고가 됩니다. 리눅스 커널의 어셈블리 코드 부분은 만들면서 배우는 OS 커널의 구조와 원리에서 많은 부분을 참조했습니다.
•리눅스 커널의 이해, 2판, 한빛미디어
•만들면서 배우는 OS 커널의 구조와 원리, 한빛미디어
• 리눅스 커널 프로그래밍, 교학사
• 리눅스 매니아를 위한 커널 프로그래밍, 교학사
• 리눅스 커널 심층 분석, 에이콘
• 리눅스 커널 분석 2.4, 가메
• Operating System Cencepts, 6판, 홍릉
이 글은 리눅스 커널을 처음 공부하는 분들에게만 적합하며, 이미 잘 알고 계시는 분들에게는 적합하지 않을 수도 있습니다. 본 기사에서는 다음 주제들을 다룰 것입니다.
1. Memory Model
2. i386 CPU에서의 메모리 관리
3. 리눅서 커널에서의 메모리 관리
4. 커널에서의 코드
메모리 모델
예를 들어서, 1M 메모리를 가진 시스템이 있습니다. 이 시스템에서 메모리를 300k 사용하는 프로그램 A가 있고, 500k를 사용하는 프로그램 B가 있습니다. 그런데, 프로그램 A는 데이터가 많아질수록 더 많은 메모리를 사용하게 되어 있어서 600k의 메모리를 사용하게 되었습니다. 이런 경우에는 메모리가 프로그램 A와 B가 서로 충돌하게 되어 더 이상 프로그램을 실행할 수 없게 될 것입니다. 프로그램을 작성하면서 계산기 프로그램이 내 프로그램의 메모리 영역을 침범하면 안되는데라고 고민하면서 프로그램을 작성하지는 않을 것입니다. 이와 같이 다양한 프로그램들이 메모리를 사용할 수 있게 하기 위해 OS는 메모리를 관리합니다.
메모리 모델의 종류
메모리를 관리하는 방법은 세그먼트(Segment) 기법과 페이징(Paging) 기법이 있습니다. 우리가 흔히 보는 책은 페이지를 매기는 방법이 두 가지가 있습니다. 예를 들어, 1,000 페이지짜리 책이 있을 때 페이지를 1번부터 1,000번까지 모두 매겨놓은 책이 있는가하면, 책을 챕터별로 나누어서 각 챕터에서 몇번째 페이지라고 표기하는 방법이 있습니다. 선형적으로 일괄되게 페이지를 매기는 방법을 페이징이라 하고, 각 챕터별로 책을 나누고, 챕터에서 몇번째 페이지(Offset)라고 나누어 관리하는 방법을 세그먼트라고 합니다.
현대 운영체제는 정확하게 세그먼트와 페이징으로 나누어 관리하기 보다는 이 두가지를 적절하게 혼합된 형태를 사용합니다.
여기까지는 메모리를 관리하는 방법을 이론적으로 나눈 것이고, CPU에서 메모리를 관리하는 것은 다릅니다. 즉, OS에서 메모리를 관리하는 방법은 OS를 제작하는 사람이 마음대로 정할 수 있는 것이지만 실제로 CPU와 데이터를 주고 받을 때는 CPU에 맞춰서 데이터를 주고 받아야 합니다. 우리가 사용하는 x86 CPU는 리얼 모드(Real Mode)와 보호 모드(Protected Mode)를 사용합니다. 리얼 모드는 예전에 도스(DOS)를 사용하던 시절에 사용하던 모드로 1M 까지의 메모리를 사용할 수 있습니다. 보호 모드에서는 메모리를 0-4G까지 사용할 수 있습니다. 요즘에는 모두들 512M 이상의 램을 장착해서 사용하는 것이 보편적이니 리얼 모드는 몰라도 되지 않아라고 생각할 겁니다. 그러나, 시스템이 처음 전원이 들어가고, 부팅이 될 때는 리얼 모드로 실행되고, 그 이후에 보호 모드로 넘어가게 됩니다. 그렇게 때문에 커널을 학습하는 사람들은 CPU에서 메모리를 관리하는 방법이 리얼 모드일때와 보호 모드일 때 다르다는 것을 알아야 합니다. 이에 대해서는 뒤에서 보다 자세히 설명하도록 하겠습니다.
커널의 메모리 모델
리눅스 커널이 생각하는 메모리 모델은 크게 두 가지 뿐입니다. 하나는 물리 메모리(Physical Memory)이고, 다른 하나는 가상 메모리(Virtual Memory)입니다.
많은 분들이 들어보았을 이야기는 프로세스 하나당 4GB까지의 메모리 공간을 가진다는 것입니다. 즉, 스타크래프트도 4GB의 메모리 공간을 사용한다고 생각하고, 인터넷 익스플로러도 4GB의 메모리 공간을 사용한다고 생각합니다. 잠깐만요! 저는 PC에 램이 512M 밖에 없는데요? 라고 생각할 수 있습니다.
잠시 생각하면 알 수 있는 것처럼 모든 프로그램은 4G라는 메모리를 모두 사용하는 것이 아닙니다. 실제로는 매우 작은 일부만 사용할 뿐입니다. 그러니 사용하지 않는 부분은 무시하고, 사용하는 부분만 메모리에 갖고 있으면 됩니다.
프로세스는 4G의 공간이 전부 자기것이라고 생각하고, OS는 프로세스가 실제로 사용하는 부분만 실제 메모리에 올려놓으면 됩니다. 즉, 가상 공간과 실제 메모리 공간을 연결할 수 있는 변환 테이블이 하나 있으면 되겠네요!
그림1. 프로세스 A의 가상 공간과 실제 메모리
그림에서 볼 수 있는 것처럼 프로세스 A는 페이지 1, 4, 7번을 사용하고 있습니다. 그리고 이들 각각은 실제 메모리 프레임 5, 3, 1에 저장되어 있습니다. 이와 같은 방법을 사용하기 때문에 각 프로세스는 각자가 4G의 공간을 사용하고 있다고 생각하고, 다른 프로그램이 사용하는 메모리 공간에 대해 염려하지 않고 프로그램을 작성할 수 있는 것입니다.
x86 아키텍처의 메모리 모델
CPU는 연산을 위해 메모리와 데이터를 주고 받습니다. 즉, CPU가 메모리를 어떻게 이용하는지 알고 있어야합니다. CPU마다 메모리를 이용하는 방법은 각기 다르지만, 여기서는 가장 흔하게 사용되는 x86 CPU에 대해서 살펴볼 것입니다.
그림2. x86 CPU의 메모리 모델
x86 CPU는 32bit 환경이라고 얘기합니다. 즉, 메모리도 32bit에 해당하는 2의 32승 = 4G까지 사용할 수 있습니다. 각 페이지를 4096 바이트로 나누어서 관리하고 있습니다. 즉, 2^12 = 4096입니다. 따라서, 12 비트는 각 페이지의 위치를 가리키기 위해서 사용됩니다.
4G의 공간을 4096 페이지 크기로 나누면 1,048,576이고, 이 숫자의 의미는 4G의 메모리 공간을 4k 크기의 페이지로 나누어 관리하기 위해서는 페이지 테이블이 1,048,576개나 필요하다는 의미가 됩니다. 즉, 2^20 = 1,048,576이고, 1개의 PTE는 4 바이트이기 때문에 페이지 테이블이 차지하는 메모리의 크기는 1,048,576 * 4 = 4M가 됩니다. 즉, 하나의 프로세스가 4G의 메모리 공간을 관리하는 페이지 테이블을 유지하기 위해서는 4M가 필요하다는 것입니다. 프로세스 1개 생성에 4M를 무조건 사용한다는 것은 꽤나 큰 낭비입니다.
20 bit table인 경우: 2^20 = 1,048,576 = 1M
1M * 2^12(4096) = 4G
PTE = 4 bytes, 1M * 4 = 4M each process
그렇다면, 20비트를 한꺼번에 이용하는 대신에 10비트씩 나누어서 사용하면 어떨까요?
2의 10승은 1024개이고, 한 항목은 4 바이트를 차지하므로 1024 * 4 = 4096 = 4k를 사용하게 되고, 4k는 메모리에서 1 프레임만 차지합니다.
그래서 그림2와 같이 페이지 디렉토리에 10비트, 페이지 테이블에 10비트를 사용합니다.
Page Directory = 1024개 * 4 bytes = 4k = 1 page
Page Table = 1024개 * 4 bytes = 4k = 1 page
간단하게 C언어의 정의대로 적어보면 다음과 같습니다.
unsinged int table[1024*1024];
unsigned int directory[1024], table[1024];
첫번째는 20비트를 사용했을 때의 배열 선언이고, 두번째는 10비트씩 나누어서 디렉토리, 테이블로 사용할 때의 선언입니다. 물론, 리눅스 커널의 선언이 이렇게 되어 있다는 것은 아닙니다.
첫번째 배열 선언이 차지하는 크기를 생각해보면 4M이고, 두번째 배열 선언이 차지하는 크기는 8k입니다.
0xC1234567이라는 논리 주소가 주어졌을 때 실제로 CPU에서 어떻게 실제 메모리를 찾아가는지 살펴보겠습니다.
그림3. 논리 주소
0xC1234567이라는 16 진수를 2진수로 풀어서 쓰면 11000001001000110100010101100111이며, 이를 각각 10, 10, 12 비트씩 끊으면 위 그림과 같다.
그림2에 나온 것처럼 CPU에는 CR3 레지스터가 있으며, 이 레지스터는 메모리 관리를 위한 페이지의 출발지 정보를 갖고 있다. 따라서 CR3 레지스터의 값을 읽어서 페이지 디렉토리가 시작하는 위치를 알아내고, 상위 10비트 1100 0001 00번째에 해당하는 위치로 디렉토리에서 이동하는 것이다. 16진수로는 0x304이며, 10진수로는 772가 된다. 772라는 의미는 페이지 디렉토리의 1024개 중에서 772번째 항목을 의미한다. 실제로는 773번째지만, PC에서는 값을 0부터 세어나가기 때문에 혼동하지 않게 0번째, 1번째, 2번째, 처럼 772번째라고 하겠다. 한 항목이 4바이트이므로 772 * 4 = 3088 로 이동해야한다. 여기서 읽어들인 값은 다시 페이지 테이블의 시작주소를 가리킨다. 페이지 테이블에 저장된 값 1000 1101 00 = 0x234 = 567이므로, 567번째 항목으로 이동해야 한다. 마찬가지로 각 항목이 4바이트 이므로 567 * 4 = 2256 위치로 이동해서 물리 프레임의 메모리 주소를 알아낸다. 마지막 오프셋은 여기서 알아낸 메모리 주소 값에 대한 상대위치를 나타내는 값이기 때문에 값을 단순히 더하기만 하면 된다.
2256위치에서 읽어들인 값이 0x40000이고, 오프셋의 값이 1383이면 실제 메모리 주소의 위치는 0x41383이 된다.
리눅스 커널의 메모리 모델
리눅스 커널은 64비트 선형 주소를 사용한다. 커널에서 64비트 주소를 사용하는 이유는 Alpha CPU와 같이 64비트 주소를 사용하는 시스템을 지원하기 위해서이다.
그림4. 리눅스 커널의 메모리 모델
리눅서 커널도 x86 CPU와 마찬가지로 메모리 관리의 효율성을 위해 페이지 디렉토리를 글로벌 디렉토리와 미들 디렉토리로 나누어서 관리한다. 즉, x86 CPU에서 2단계 페이징을 사용한다면 커널에서는 3단계 페이징을 사용하는 것이 차이점이다.
글로벌 디렉토리는 pgd_t, 미들 디렉토리는 pmd_t, 페이지 테이블은 pte_t로 나타내며, 오프셋은 상대위치이기 때문에 따로 나타낼 필요는 없다.
x86에서는 2단계를 사용하고, 리눅스 커널에서는 3단계를 사용한다면 커널은 x86 환경에서는 어떻게 해야할까? x86 CPU를 지원하기 위해 별도로 2단계 페이징을 만들어야 할까? 라고 생각할 수 있는데 실제로 커널은 위 구조를 그대로 유지하면서 2단계 페이징을 지원하는 방법을 택했다. 즉, 미들 디렉터리를 1개만 사용하는 것이다. 이렇게 하면 커널의 코드를 크게 변경하지 않으면서 64비트 환경과 32비트 환경을 쉽게 지원할 수 있다.
각 시스템마다 메모리 관리를 위해 사용하는 비트수는 다르기 때문에 위 그림에서 몇 비트씩 사용하는지 명시하지 않았다. 물론, 특정 플랫폼마다의 비트수를 적는다면 적을 수 있지만 여기서는 그렇게 하지 않았다.
x86 CPU와 커널에서 메모리를 찾는 방법을 보면 먼저 CR3 레지스터에서 글로벌 디렉터리의 시작 주소를 알아내고, 글로벌 디렉토리에서 몇번째 위치인지 알아낸다고 했다. 여기에 쓰이는 함수가 pgd_offset()이다. 마찬가지로 미들 디렉토리에서의 위치를 알아내는 것은 pmd_offset, 페이지 테이블에서의 위치를 알아내는 것은 pte_offset이다. pgd_offset, pmd_offset, pte_offset은 모두 2개의 인자를 갖는다.
pgd_offset(mm, address)인데 mm은 메모리 관리를 위한 구조로 각 프로세스마다 1개씩 갖고 있다. 즉, 페이지 글로벌 디렉토리의 시작 위치가 되며, address는 페이지 글로벌 디렉터리에서 몇 번째 위치라는 것을 나타낸다. 마찬가지로 pmd_offset의 첫번째 인자는 페이지 미들 디렉토리의 시작위치를, 두번째 인자는 페이지 미들디렉토리의 몇번째 페이지를 인자로 받는다. pte_offset도 동일하다. Redhat 9에 포함된 커널 2.4.20-8 버전에서는 pte_offset 대신에 pte_offset_kernel을 사용하면 된다. 상위 버전의 커널에서는 pte_offset으로 이용할 수 있다.
이들 함수(정확히는 매크로)를 이용하면 프로세스가 실제로 이용하고 있는 물리 메모리를 알아낼 수 있다. 이들 매크로는 arch/asm-i386/pgtable.h, pgtable-3level.h에서 찾아볼 수 있다. 참고로 실제로 존재하지 않는 페이지 글로벌 디렉토리, 미들 디렉토리 등을 액세스하려하면 중대한 커널 오류가 발생할 수 있다. 따라서, 페이지를 액세스하기 전에 각각 pgd_present, pmd_present, pte_present를 사용해서 실제 페이지가 있는지 확인하고 사용해야 한다.
프로세스에서 바라본 메모리
프로세스마다 4G의 가상 공간을 사용한다고 얘기했다. 그리고, 프로세스마다 메모리 관리를 하기 위해 페이지 글로벌 디렉토리, 페이지 테이블과 같은 구조를 갖고 있다고 했다. 프로세스를 나타내는 구조체는 task_struct이며, 여기에는 메모리 구조를 나타내는 mm_struct mm이 있다. mm은 메모리 관리를 위한 구조체이며, pgd_t* pgd는 페이지 글로벌 디렉토리의 시작 위치를 가리킨다. 즉, pgd가 가리키는 값과 CR3 레지스터가 가리키는 값이 같다. 그 이후부터는 앞에서 설명한 것처럼 각 페이지별로 주소를 찾아서 실제 메모리상의 프레임을 찾아간다.
그림5. 프로세스에서 바라본 메모리
이를 자세하게 표현하면 그림6과 같습니다. 각각의 프로세스는 task_struct 구조체로 표현되며, 이를 간단히 PCB(Process Context Block, 컨텍스트 문맥)이라고 이야기한다. 커널에는 프로세스 ID로 해당 PCB를 찾아내는 함수가 있는데 이 함수가 find_task_by_pid(pid)이다. 이 함수는 프로세스 ID, PID를 인자로 넘겨 받으면 task_struct에 대한 것을 반환해준다.
물론, 현재 프로세스는 current로 접근할 수 있지만, 다른 프로세스에 대한 task_struct를 얻어오려면 find_task_by_pid를 사용해야 한다. task_struct에는 mm이 있고, 이 mm이 mm_sturct 자료구조를 가리킨다.
그림1을 생각해보면 프로세스는 연속적인 가상 메모리를 할당 받는 것도 아니라 여러 개의 가상 메모리 블록을 할당받는다. 즉, 연속적으로 할당 받을 수도 있고, 따로따로 할당 받을 수도 있다는 얘기다. 이를 위해서 mm_struct에 보면 각각의 가상 메모리 블록을 관리하는 vm_area_struct 구조체가 있다. 그리고 vm_area_struct에는 각각 vm_start와 vm_end가 있는데 이는 가상 메모리 공간에서의 시작 위치와 마지막 위치를 가리킨다. 또한 vm_area_sturct* vm_next는 자신과 같은 형태의 구조체를 다시 가리키고 있는데, 이는 다른 가상 메모리 블록을 가리킨다. 즉, 단일 연결 리스트(Singly Linked List)로 연결되어 있다. vm_next를 따라 프로세스가 사용하는 전체 가상 메모리 공간을 알아낼 수 있다. 만약, vm_next가 NULL인지 아닌지를 알아내면 가상 메모리 블록의 끝을 알아낼 수 있다.
그림6. 프로세스에서 바라본 메모리 관리
마지막으로 task_struct에는 mm_struct로 선언된 변수가 두 가지가 있다. 하나는 mm이고, 다른 하나는 active_mm이다. mm은 프로세스가 사용하는 메모리 공간을 나타내고, active_mm은 CPU에 의해 현재 제어중인 주소공간을 가리킨다. 프로세스 A에게 있어서 mm과 active_mm은 같다. 즉, A->mm == A->active_mm이다. 그러나, 커널 스레드에서는 mm은 NULL이며, 커널 스레드가 사용중인 메모리는 active_mm으로 표현된다.
Linux 커널의 아버지인 Linus는 메모리 공간을 실주소공간(Real Address Spaces)과 익명주소공간(Anonymous Address Spaces)로 나눈다. 사용자 프로세스가 사용하는 주소 공간을 실주소공간아리하고, 커널 스레드가 사용하는 공간을 익명주소공간이라 하는 것이다.
모든 커널 스레드는 익명주소공간을 사용하며, 사용자 프로세스가 사용하는 실주소공간에 대해서는 관여하지 않는다.
foo라는 프로세스 A를 실행한다고 하자. 이 경우 A->mm == A->active_mm = foo일 것이다. 이때 커널 스레드 B에 의해 선점당한 경우 B->mm = NULL이지만, A->active_mm = foo를 여전히 가리키게 된다. 즉, 커널 스레드는 실주소공간을 신경쓰지 않지만, 작업 A가 다시 로드되었을 때 mm을 다시 로드하지 않기 위해 active_mm을 사용하는 것이다.
스왑
실제 메모리 사용량보다 더 큰 메모리가 필요한 프로그램을 실행할 수 있는 것은 가상 메모리 덕분이다. 앞에서는 가상 메모리에 대해서 살펴보았는데, 사용중이지 않은 부분은 스왑으로 저장해서 메모리에 여유공간을 확보하는 것이 스왑의 역할이다.
앞의 그림5에서 살펴본 것처럼 스왑을 한다는 것은 실제 메모리의 프레임을 디스크로 저장하는 것을 의미한다. 실제 메모리 프레임을 찾기 위해서는 페이지 테이블의 위치를 알아야하고, 페이지 테이블의 위치를 알기 위해서는 페이지 미들 디렉토리의 위치를 알아야한다. 마찬가지로, 페이지 미들 디렉토리의 위치를 알기 위해서는 페이지 글로벌 디렉토리의 위치를 알아야 한다. 이들 프로세스는 가상 메모리로 관리되고 있으니 가상 메모리 구조를 찾아봐야하고, 다시 실제 메모리 공간도 찾아봐야 한다. 즉, swap_out 함수는 이러한 순서들을 찾아가며 실제 메모리 프레임을 찾아가는 역할을 하고, 메모리 프레임을 디스크에 저장하는 것은 try_to_swap_out 함수의 역할이다.
그림7. 스왑의 흐름
kswapd 함수는 daemonize 함수를 호출해서 자신을 데몬으로 등록시키고, 무한 루프를 돌면서 kwapd_can_sleep 함수를 호출한다. 이 함수는 지금 스왑 작업을 해도 되는지 아닌지를 판별하며, 이를 판별하기 위해서는 다시 kswapd_can_sleep_pgdat를 호출해서 페이지 글로벌 디렉토리에서 스왑이 필요한 페이지가 있는지 없는지를 판별한다. 스왑이 필요한 페이지가 하나라도 있으면 kswapd_balance를 호출한다. kwapd_balance는 메모리의 균형을 맞춰준다. 마찬가지로 이 함수도 kswapd_balance_pgdat를 호출하여 페이지 글로벌 디렉토리를 확인한다. try_to_free_pages 함수에서 try_to_free_pages_zone을 호출해서 사용할 수 있는 페이지 영역을 찾아보고, 사용할 수 있는 페이지가 부족한 경우에는 필요한 페이지를 확보하기 위해 shrink_caches를 호출한다. shrink_caches는 캐시들을 돌아다니며 비울 수 있는 캐시인지 판별하기 위해 shrink_cache 함수를 사용한다.
전체적인 흐름은 이렇게 되어 있으며, 각 프로세스에서 사용중인 스왑 공간은 task_struct의 swap_address로 알 수 있다.
스왑 정책
커널의 스왑 정책에서 사용할 수 있는 방법은 여러가지가 있지만, 리눅스 커널에서는 LRU(Least Recently Used) 정책을 사용한다고 알려져 있다. LRU는 가장 적게 사용된 페이지를 스왑으로 대체시키는 것이다.
메모리 페이지를 LRU 정책에 따라 스왑시키려면 해당 메모리 페이지가 액세스 된 적이 있는지 알아낼 수 있는 방법이 있어야 한다. 각 페이지가 액세스 된 시간을 기록해서, ‘아, 이 페이지는 1시간 전에 액세스했고, 이 페이지는 5분전에 액세스했네’라는 사실을 이용할 수도 있을 것이다. 단, 이렇게 한다면 액세스 될 때마다 시간을 기록하고, 각 페이지의 시간을 기록하고 유지하는 것만으로도 굉장히 높은 작업부하가 걸릴 것이라고 예상할 수 있을 것이다. 이런 스왑 정책은 OS가 단독으로 하기엔 어려운 부분이다. CPU에서는 이를 위해 액세스 비트(Access Bit)를 제공한다. 이 비트는 이 페이지가 접근된 적이 없으면 0, 있으면 1로 설정된다. 그림8에서 A가 액세스 비트를 나타낸다. 액세스 비트는 페이지에 접근할 때 CPU에서 자동으로 1로 설정하지만, CPU가 이를 다시 0으로 설정할 수는 없다. 0으로 설정할 수 있는 것은 오직 커널 뿐이다.
그림8. 페이지 엔트리
U/S는 사용자 프로세스가 접근할 수 있으면 1이고, 커널만 접근할 수 있으면 0으로 설정된다. R/W는 0이면 읽기만 가능하고, 1이면 읽기/쓰기가 모두 가능하다. P는 Present Bit라는 것으로 페이지가 메모리상에 존재하는지를 나타낸다. 즉, 페이지가 디스크로 스왑 되었으면 0이 된다. 프로세스가 이 페이지를 접근하려하면 P 비트가 0이기 때문에 페이지 폴트 인터럽트 #14가 발생하고, 디스크에서 다시 메모리로 이 페이지를 읽어들이고, P 비트를 1로 설정하게 된다.
메모리 관리와 관련된 부분은 OS가 독단으로 결정할 수 있는 것이 아니며, CPU와 OS가 서로 조화를 이루어가며 관리하는 부분이다.
코드로 보는 리눅스
8086 시스템은 과거에 20개의 어드레스 핀을 가진 16비트 시스템이었다. 즉, 2^20 = 1M까지 사용할 수 있는 시스템이었다. 이 의미는 1M 이상의 메모리를 사용할 수 없다는 것이다. 1M + 1번째를 접근하려 하면 1번째로 접근하게 된다. 이는 마치 프로그래밍 언어에서 만나는 정수 오버플로우와 같다. 1M + 1 = 1로 만들려면 어떻게 하면 될까? 2^20은 16진수로 0x100000이고, 2진수로는 100000000000000000000이다. 1M를 넘어가는 비트가 공교롭게도 가장 맨 앞의 비트이다. 즉, 맨 앞의 1을 0으로 만들어 주기만 하면 된다. 11111111111111111111 + 1을 하면 100000000000000000000이 되어야 하는데 20번째 비트를 0으로 만들면 결과 값은 0이 된다. +2를 하면 결과값은 1이 될 것이다.
이를 위해 8086 시스템에서는 20번째 핀을 키보드 인터럽트 핸들러인 8042와 AND 게이트로 연결해 놓았다. 20번째 핀이 켜지지 않으면 사용자는 항상 저 주소를 이용할 수 없다.
펜티엄 4에서 DOS용 응용 프로그램을 실행할 수 있다는 의미는 하위 호환성이 좋다는 의미이기도 하지만, 위와 같은 단점도 고스란히 물려받았다는 의미가 된다.
요즘과 같이 512M 램을 사용하는데, 저걸 알아서 뭐해요? 라고 되물을수도 있다. 그러나 A20을 켜주지 않으면 20번째 비트가 항상 0이 되기 때문에 1M = 0이 되고, 3M = 0이 된다. 즉, 1M에 해당하는 메모리 주소를 CPU가 액세스하려하면 0번째를 가리키게 된다. 사용자는 1, 3, 5, 7…과 같이 홀수번째 메모리를 전혀 사용할 수 없게 된다. 그렇게 때문에 부팅 과정에서 CPU가 리얼 모드에서 보호 모드로 넘어가기전에 반드시 A20 게이트를 켜야한다.
리눅스 커널의 소스 코드를 보면 그런 부분이 있다. movb $0xDF, %al이 있고, 옆에는 주석으로 A20 게이트를 켠다고 되어 있다. 이 부분의 값은 몰라도 된다. 저것은 CPU 매뉴얼에 있는 특정한 명령어인 것이다.
여기서는 lgdt gdt_48을 볼 수 있다. lgdt 명령어는 전체 커널 소스에서 단 한번만 사용된다. CPU는 리얼 모드에서 보호 모드로 넘어가기전에 글로벌 디스크립터(Global Descriptor)를 작성해야 한다. 즉, 4G에 해당하는 메모리를 어떻게 사용하겠는가를 설계하는 명세서와 같은 역할을 한다. 코드 세그먼트 디스크립터, 데이터 세그먼트 디스크립터, 비디오 세그먼트 디스크립터등을 지정할 수 있다. gdt_48은 명령어가 아니라 이러한 디스크립터를 적어놓은 곳으로 C언어의 struct와 같은 것이다.
리얼 모드에서 보호 모드로 넘어가는 순서는 1. 디스크립터를 정의한다. 2. lgdt 명령어로 디스크립터를 로드하고 보호모드로 전환한다. 이다.
CPU에는 명령어를 실행하는 부분이 3가지로 나누어져 있다. 첫번째는 명령어를 읽어들이는 부분, 두번째는 명령어를 해석하는 부분, 세번째는 명령어를 실행하는 부분이다.
즉, lgdt 명령어를 실행하게 되는 순간에 읽기 유닛, 해석 유닛에 이미 2개의 명령어가 들어가 있다. 보호모드로 전환된 다음에 리얼 모드에서 들어가 있던 명령어가 실행되면 안되니까 최소한 읽기, 해석 유닛의 명령을 무시하기 위해 두 스텝을 쉬어줄 필요가 있다. 따라서, lgdt 명령어를 실행한 다음에 어셈블리로 nop(No Operation: 아무일도 하지마!)를 2번 실행해주는 것이 관례다. 그런데, 커널 소스에선 nop 대신에 call delay를 사용하는 것 같다고 나름대로 추측할 수 있었다. nop 명령어를 커널에선 사용하지 않는다.
다음으로 첫번째 줄을 보면 lidt 명령이 있다. 이것은 인터럽트 디스크립터를 로드한다. 즉, Devide By Zero(인터럽터 0번)이라든가, 페이지 폴트(인터럽터 14번) 같은 인터럽트가 발생했을 때 이를 처리할 루틴의 위치를 지정하는 부분이 idt_48이고, lidt는 이를 메모리에 로드해주는 것이다.
굳이 이렇게 GDT를 꺼내든 이유는 <<리눅스 커널의 이해>>의 2장 메모리 관리 부분의 처음 1/2 정도가 전부 이 GDT 구조를 설명하는데 할애되어 있다고 느꼈기 때문이다. 책만 펼치면 잠이 쏟아질 만큼 졸린데, 이는 어셈블리와 CPU 구조에 대한 이해조차 없이는 책을 이해하기 어렵기 때문이라 생각했다. 즉, 내공이 부족한 내가 보기엔 어려운 책이다.
이들 어셈블리 코드는 arch/i386/boot에 있으며, 비디오 디스크립터는 video.S에 정의되어 있다.
위 코드처럼 0xC0000000가 3G 영역을 가리킨다. 커널이 3G위의 영역을 사용한다는데 실제로 그 값이 있는지 확인해 본 부분이다.
여기서는 앞에 CR4 레지스터가 보인다. CPU에는 CR0-CR4까지의 레지스터가 있다. 이중에서 CR3는 페이지 글로벌 디렉토리의 위치를 가리키며, CR4 레지스터는 PAE 확장을 사용할 것인가를 설정한다. 펜티엄 프로 이후에는 어드레스 핀이 4개가 더 추가되어서 4G가 아니라 64G까지 사용할 수 있게 해준다. 따라서, 이 값이 설정된 경우에 CR4 비트를 1로 설정해서 PAE 확장을 사용하게 설정해 주는 부분이다.
movl %eax, %cr3에서 페이지 테이블이 시작하는 위치를 CR3 레지스터에 저장하고 있다.(GAS, GNU Assembler는 AT&T 스타일을 따르고 있어서 어셈블리 명령어 인자 위치가 서로 반대다. mov a, b는 B의 값을 A에 넣는다이지만 AT&T 스타일에서는 A의 값을 B에 넣는다가 된다)
마치며
아직은 커널을 잘 알지 못하고 커널을 공부하는 입장에서 준비된 글입니다. 국내에 나와있는 다양한 커널 책들을 많이 참고했습니다. 아직 다루지 못한 부분들이 많습니다. 커널 소스에 대한 세세한 설명보다는 커널의 전체적인 흐름을 다루는 것이 세미나에는 더 적합하다고 판단해서 전체적인 흐름을 다루는데 중점을 두었습니다. kmalloc과 vmalloc의 차이점을 다루는 것 보다는 전체적인 흐름이 더 중요하다고 생각했습니다. 흐름에 대한 이해를 바탕으로 소스 코드를 살펴보는 것이 이해에 더 도움이 된다고 생각합니다.
레퍼런스
각각의 책마다 같은 부분을 보아도 설명이나 보여주는 부분이 다릅니다. 결국, 저자가 커널을 바라보는 방식에 대해 생각해보는 기회도 되고, 책을 가이드삼아 커널을 직접 찾아보며 전체를 바라볼 수 있는 안목을 기르는 것은 자신의 몫이라 생각됩니다. 주로 리눅스 커널 프로그래밍을 많이 참고했으며, 리눅스 커널 심층 분석은 커널 API 이해에 많은 도움이 되었습니다. Operating System Concepts는 운영체제가 시스템을 관리하는 다양한 방법과 알고리즘에 대한 해설이 중심이고 이를 토대로 리눅스 커널이 채택한 방법을 살펴보는 데 좋은 참고가 됩니다. 리눅스 커널의 어셈블리 코드 부분은 만들면서 배우는 OS 커널의 구조와 원리에서 많은 부분을 참조했습니다.
•리눅스 커널의 이해, 2판, 한빛미디어
•만들면서 배우는 OS 커널의 구조와 원리, 한빛미디어
• 리눅스 커널 프로그래밍, 교학사
• 리눅스 매니아를 위한 커널 프로그래밍, 교학사
• 리눅스 커널 심층 분석, 에이콘
• 리눅스 커널 분석 2.4, 가메
• Operating System Cencepts, 6판, 홍릉
Copyright © 2006 Hanbit Media, Inc.
'Unix Linux' 카테고리의 다른 글
| LD_ASSUME_KERNEL (0) | 2006.09.22 |
|---|---|
| VMWare를 이용하여 오픈솔라리스 시작하기 (0) | 2006.06.30 |
| how to create and use program libraries on Linux (0) | 2006.05.11 |